
.jpg?width=2000&height=500&name=kognic-camera-vs-lidar-annotation-comparison-banner%20(1).jpg)
Camera annotation and LiDAR annotation are the two primary approaches to labeling sensor data for autonomous driving. Camera annotation involves labeling 2D image data (bounding boxes, segmentation masks, lane markings), while LiDAR annotation involves labeling 3D point cloud data (cuboids, 3D tracking, spatial segmentation). Most production AV systems require both. Choosing the right approach depends on your model architecture, deployment environment, and safety requirements.
Autonomous driving systems don't see the world the way humans do. They perceive it through sensors (cameras, LiDARs, radars) and the training data that defines what those sensors "understand" is built through annotation. Choosing which sensor data to annotate, and how, is one of the most consequential decisions in any AV data pipeline.
Camera and LiDAR are the two primary perception sensors in production autonomous systems today. They work differently, capture different information, and require fundamentally different annotation approaches. For teams building perception models, the choice of which to annotate (or whether to annotate both) directly affects what your model can learn, where it will fail, and how much it costs to produce training data at scale.
This guide breaks down the technical differences, what annotation looks like for each, when camera annotation makes sense, when LiDAR annotation is the right call, and how sensor fusion changes the equation.
What Cameras Capture, and What They Miss
Cameras produce 2D images in the visible light spectrum. They capture color, texture, contrast, and fine-grained visual detail that no other automotive sensor can match. A camera sees lane markings, traffic signs, facial expressions on pedestrians, brake lights, and the subtle visual cues that human drivers rely on instinctively.
The resolution is also unmatched. A modern automotive camera captures tens of megapixels per frame at high frame rates, producing dense visual information across the full scene. This richness is precisely why cameras remain the backbone of perception systems at every autonomy level. They're informative, cheap relative to other sensors, and they scale well.
But cameras have hard limits. They depend entirely on light. Performance degrades in fog, heavy rain, direct sunlight glare, and at night. More critically, cameras have no native depth perception. A standard camera captures a 2D projection of a 3D world. Estimating depth from a single camera requires learned inference, which introduces uncertainty. Stereo camera rigs improve this, but depth estimation from cameras remains fundamentally less precise than what a LiDAR can deliver directly.
What LiDAR Captures, and Where It Falls Short
LiDAR (Light Detection and Ranging) works by emitting laser pulses and measuring the time it takes for reflections to return. The result is a point cloud: a dense 3D map of the environment with precise depth measurements for every point. Where a camera gives you a rich 2D image, LiDAR gives you exact spatial geometry in three dimensions.
This has enormous practical value. LiDAR tells you precisely how far away an object is, its height, width, and shape in 3D space, and how it moves over time. It doesn't care about lighting conditions. It works in complete darkness because it generates its own illumination. Fog and light rain reduce its range, but it degrades more gracefully than a camera in low-light conditions.
The downsides are cost and density. LiDAR hardware is expensive, even as prices have dropped significantly in recent years. And point clouds, while spatially precise, are sparse compared to camera imagery. You get geometry, but not color, not texture, not the fine visual detail that makes object recognition tractable. A pedestrian in a LiDAR point cloud is a cluster of points. In a camera frame, it's a person with discernible clothing, posture, and context.
Annotation Types: 2D vs 3D
The annotation work required for camera data and LiDAR data is fundamentally different. So is the skill, tooling, and cost involved.
Camera annotation is primarily 2D work. The most common annotation types include:
- 2D bounding boxes — rectangular regions around objects of interest (vehicles, pedestrians, cyclists, signs). Fast to produce and widely used for object detection training.
- Polygons and instance segmentation — precise pixel-level outlines around objects. More labor-intensive than bounding boxes but required when shape matters, such as for drivable area or obstacle boundary detection.
- Semantic segmentation — pixel-by-pixel class assignment across the full frame. Essential for scene understanding models that need to classify every pixel (road, sidewalk, building, sky, vehicle, etc.).
- Keypoints and pose estimation — marking specific anatomical or structural points, used for pedestrian pose estimation and traffic sign localization.
- Lane annotations — polylines along lane boundaries, critical for lane-keeping and lane change behavior.
These task types are well understood, tooling is mature, and a large global workforce has experience performing 2D annotation. Throughput is relatively high and per-frame costs are lower than LiDAR work.
LiDAR annotation is 3D work, and it's substantially more complex. Common annotation types include:
- 3D bounding boxes — cuboids placed around objects in 3D space, defined by position, dimensions, and heading angle. This is the standard for object detection in point clouds and requires annotators to reason about spatial geometry rather than 2D appearance.
- Point cloud segmentation — assigning class labels to individual points or clusters within the point cloud. Required for ground plane estimation, obstacle detection, and scene parsing.
- Track annotations — linking objects across frames over time, assigning consistent IDs to create object tracks. Critical for motion prediction and behavior modeling.
- Surface normal and ground truth geometry — detailed geometric annotations used in HD map production and localization.
LiDAR annotation requires different tooling (3D annotation interfaces, multi-frame synchronization), more specialized annotators, and more QA overhead because errors in 3D space are harder to catch visually than errors in 2D images. As a result, LiDAR annotation is more expensive per unit and slower to scale.
Kognic's annotation platform handles both annotation types with purpose-built tooling, including auto-labeling capabilities that significantly reduce the manual load for both 2D and 3D tasks.
When Camera Annotation Is the Right Choice
Camera annotation makes sense when:
You're training 2D detection or segmentation models. If your model takes image input and outputs 2D predictions (bounding boxes, segmentation masks, keypoints), then camera annotation is what you need. This covers a large share of ADAS perception models, including traffic sign recognition, lane detection, and camera-based pedestrian detection.
Cost and scale are constraints. Camera annotation is significantly cheaper per frame than LiDAR annotation. If you're producing large volumes of training data and budget is a meaningful constraint, camera-first annotation pipelines can deliver more labeled examples for the same investment.
Your deployment environment has reliable lighting. Systems operating primarily in well-lit, predictable conditions (highway ADAS, daytime urban driving) can get substantial coverage from camera data alone. The sensor's limitations matter less in controlled deployment contexts.
You need rich semantic context. Color, text, symbols, and fine-grained visual patterns are only available in camera data. If your model needs to read a speed limit sign, distinguish brake lights from tail lights, or understand lane markings, cameras are the only sensor that can provide that information.
You're doing rapid prototyping. Standing up a camera annotation workflow is faster than LiDAR. If you're iterating quickly on a new model architecture or testing a dataset hypothesis, camera annotation lets you move at higher speed.
When LiDAR Annotation Is the Right Choice
LiDAR annotation becomes necessary when:
You need precise 3D localization. Object detection in 3D space means knowing exactly where an object is relative to your vehicle in meters. That requires LiDAR. Camera-based depth estimation introduces errors that grow with distance; LiDAR provides consistent precision from near to far range.
Your models need to work in low-light or adverse conditions. LiDAR doesn't depend on ambient light. If your system needs to operate at night, in tunnels, or through light rain, LiDAR provides perception capability that cameras cannot reliably deliver.
You're building for motion prediction and planning. Understanding how objects move in 3D space (their velocity vectors, heading angles, and trajectories) is much more tractable from LiDAR than from camera. Planning systems need accurate 3D state estimates, and LiDAR is the primary source for those.
You're producing HD map ground truth. Map creation requires precise geometric measurements of road features: curbs, barriers, lane boundaries in 3D. LiDAR provides these measurements directly. Camera-based mapping exists but requires significant additional processing.
Your safety case demands it. For higher autonomy levels (L3+), where the system is responsible for dynamic responses, regulators and internal safety teams typically require demonstrated reliability across sensor modalities. LiDAR is the redundant perception layer that backs up camera-based detections in safety-critical moments.
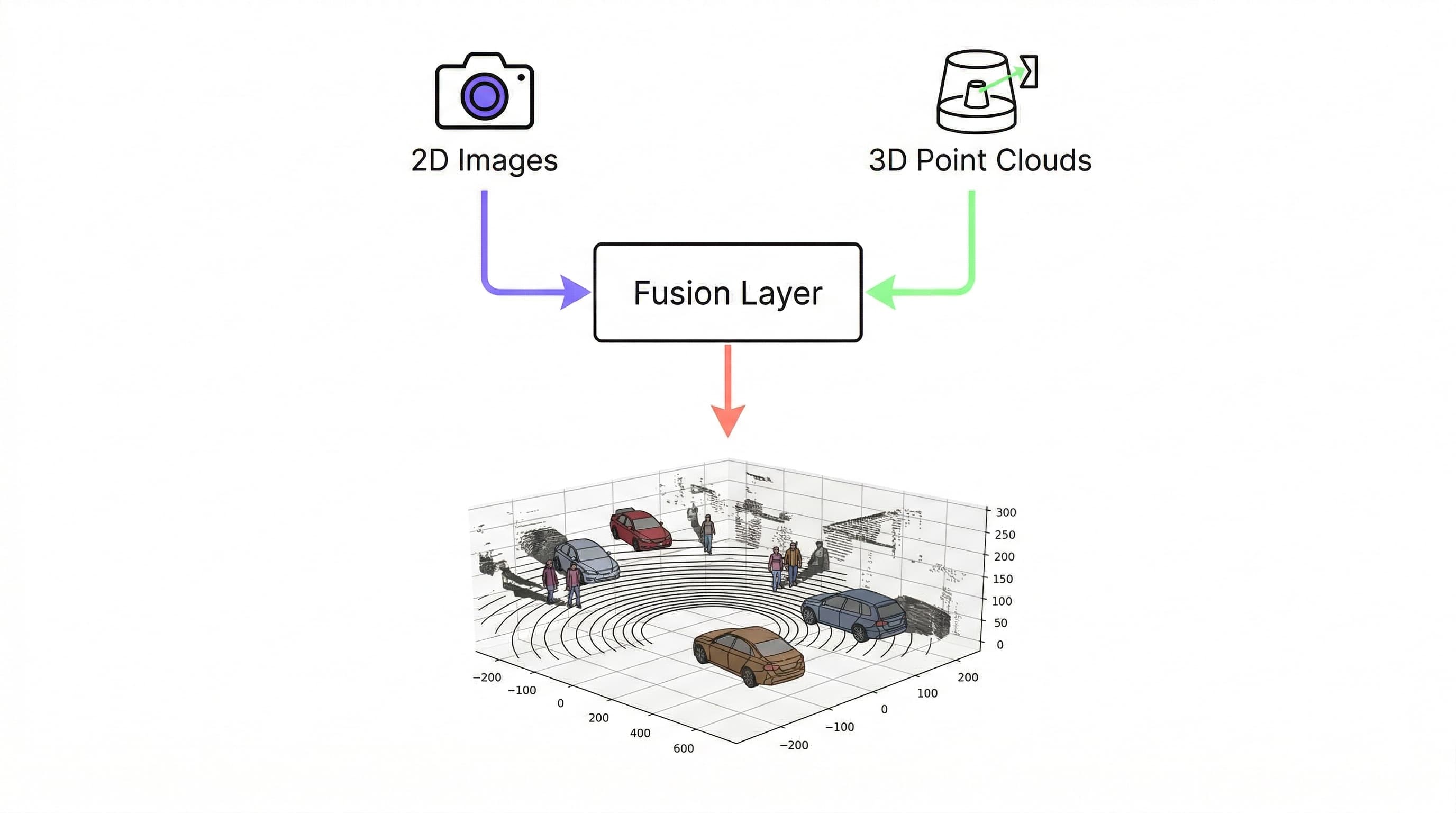
Sensor Fusion: When You Need Both
In production autonomous systems, the real answer to "camera or LiDAR?" is almost always "both." The two sensors are complementary in a deep way. Cameras provide semantic richness, LiDAR provides geometric precision. Modern perception architectures are built to fuse their outputs.
Sensor fusion annotation is more complex than annotating either modality independently. When you fuse annotations across sensors, consistency becomes critical: the 3D bounding box in the LiDAR point cloud must correspond accurately to the 2D bounding box in the camera frame, labels must match, and object identities must be synchronized across modalities. Errors in either propagate into the fused representation.
This is where annotation platforms matter more than for single-modality work. Manual multi-sensor annotation without purpose-built tooling produces inconsistent annotations that undermine fusion training. Platforms that handle temporal synchronization, cross-modal label consistency, and automated quality checks reduce the error rate significantly and reduce the annotation cost, since consistent tooling allows auto-labeling to apply across both modalities simultaneously.
Kognic's platform is purpose-built for this kind of multi-sensor annotation work. The platform handles LiDAR and camera data together, with auto-labeling that operates across sensor modalities and QA workflows designed for the consistency requirements of fusion training data.
⚠️ Stat to verify before publishing: The v1 draft cited "68% reduction in time-to-label" here. This figure originates from Language Grounding, not general sensor fusion. Confirm applicability or remove.
For a deeper look at 3D point cloud annotation specifically, including the different annotation task types, how cuboid annotation works across frames, and what quality benchmarks to target, see our guide to 3D point cloud annotation.
Camera vs LiDAR Annotation: Side-by-Side Comparison
| Factor | Camera Annotation | LiDAR Annotation |
|---|---|---|
| Working space | 2D image pixels | 3D point cloud coordinates |
| Best for | Classification, segmentation, appearance-based tasks | 3D localization, geometry, distance-critical tasks |
| Strengths | Rich texture, color, contrast; lower cost per frame | Precise 3D position; illumination-independent |
| Weaknesses | No depth information; affected by lighting conditions | Sparse data; higher cognitive load; more expensive |
| Typical annotation types | 2D bounding boxes, polygons, semantic segmentation | 3D cuboids, 3D tracking, 3D semantic segmentation |
| Throughput | Higher (faster per frame) | Lower (more complex per frame) |
| Cost per frame | Lower | Higher |
| Occlusion handling | Visually obvious | Requires inference from partial returns |
| Weather impact | Degrades in glare, darkness, shadows | Degrades in rain, fog (scattered returns) |
| When to use alone | Vision-only models, classification tasks | 3D-native architectures, depth-critical decisions |
| When to combine | Sensor fusion systems (most production AV programs) | Sensor fusion systems (most production AV programs) |
A Decision Framework
If you're deciding how to structure your annotation pipeline, here's a practical starting point:
| Factor | Camera-First | LiDAR-First | Both (Fusion) |
|---|---|---|---|
| Model type | 2D detection, segmentation | 3D detection, localization | Multi-modal perception |
| Depth required | No | Yes | Yes |
| Low-light operation | No | Yes | Yes |
| Annotation budget | Lower | Higher | Highest |
| Deployment level | ADAS (L1-L2) | L3+ | L3+ |
| Training data volume needed | High | Medium | Medium-High |
Most teams starting with ADAS features begin with camera annotation for cost and speed reasons, then add LiDAR annotation as they move toward higher autonomy levels or encounter the limits of camera-only perception. The transition point is usually when depth precision and adverse-condition resilience become hard requirements rather than nice-to-haves.
For teams already operating at L3 or developing toward L4/L5, the question is rarely camera vs. LiDAR. It's how to make the fusion annotation workflow efficient and consistent enough to scale.
Annotation Quality Matters as Much as Modality Choice
One point that often gets underweighted: the modality choice matters less than annotation quality. A large dataset of poorly labeled LiDAR data will underperform a smaller, carefully annotated camera dataset. The precision of 3D bounding boxes (heading angle accuracy, point inclusion/exclusion decisions at object boundaries, tracking consistency across frames) directly affects whether your model learns correct object geometry or noise.
This is doubly true for fusion annotation, where inconsistency across modalities creates adversarial training examples. When the camera says "car at position X" and the LiDAR says "car at position Y + 0.5m," the model has to learn which to trust. In the worst case, it learns to distrust both.
Quality-controlled annotation, with per-task acceptance criteria and systematic auditing, matters more in LiDAR and fusion contexts than almost anywhere else in the machine learning pipeline. This is the case for building annotation operations with human-in-the-loop QA rather than treating annotation as a commodity task.
Kognic's annotation services combine platform tooling with expert annotators trained specifically on automotive sensor data. The result is consistent output that holds up to the quality standards needed for safety-critical system development.
Frequently Asked Questions
What is the difference between camera annotation and LiDAR annotation?
Camera annotation labels 2D image data (bounding boxes, segmentation masks, lane markings), while LiDAR annotation labels 3D point cloud data (cuboids, 3D tracking, spatial segmentation). Camera annotation is faster and cheaper per frame. LiDAR annotation provides precise depth and spatial geometry but requires specialized tooling and more experienced annotators.
When should I use LiDAR annotation instead of camera annotation?
Use LiDAR annotation when your model requires precise 3D localization, needs to operate in low-light or adverse weather conditions, or when you're building motion prediction and planning systems. LiDAR is also typically required for safety cases at L3+ autonomy levels, where regulators expect demonstrated perception reliability across multiple sensor modalities.
What is sensor fusion annotation?
Sensor fusion annotation is the process of labeling both camera and LiDAR data together so that annotations are consistent across modalities. The 3D bounding box in the point cloud must correspond to the 2D bounding box in the camera frame, with matched labels and synchronized object identities. This cross-modal consistency is critical for training multi-sensor perception models used in production autonomous systems.
Is camera annotation cheaper than LiDAR annotation?
Yes. Camera annotation is significantly cheaper per frame because it involves 2D labeling tasks (bounding boxes, polygons) with mature tooling and a large available workforce. LiDAR annotation requires 3D spatial reasoning, specialized annotation interfaces, and more QA overhead, making it 2-5x more expensive per frame depending on the task type.
Do I need both camera and LiDAR annotation for autonomous driving?
For most production autonomous driving programs, yes. Camera provides the semantic richness needed for object classification and scene understanding. LiDAR provides the spatial precision needed for 3D localization and safety-critical distance measurements. Sensor fusion combines both to produce more reliable perception than either sensor alone.
Conclusion
Camera and LiDAR aren't competing choices. They're complementary tools that serve different purposes and require different annotation approaches. Cameras give you the visual richness needed for semantic understanding; LiDAR gives you the spatial precision needed for 3D reasoning. Most production AV systems use both, which means most annotation pipelines need to handle both.
Choosing where to invest annotation effort comes down to your model's requirements, your deployment environment, your autonomy level, and your quality standards. The teams that scale most efficiently are those that treat annotation as an engineering problem: selecting the right sensor modality for the task, building consistent workflows, and applying tooling that makes quality and throughput achievable simultaneously.
If you're building out a multi-sensor annotation pipeline or evaluating how to improve your current annotation quality and throughput, talk to the Kognic team. We work with AV developers across the full sensor stack.



.jpg)