
.jpg?width=2000&height=500&name=kognic-Edge-Cases-in-Autonomous-Driving-banner%20(1).jpg)
An edge case in autonomous driving is a rare, unexpected scenario that falls outside the normal distribution of situations a perception or planning model has been trained on. Edge cases include unusual weather, atypical road users, sensor failures, novel object configurations, and ambiguous scenarios that require human-level reasoning. Handling them well is the difference between an autonomous system that performs in controlled testing and one that handles real-world deployment. Production AV teams address edge cases through targeted data collection, scenario-aware annotation guidelines, multi-sensor consistency checks, and dataset curation that intentionally over-samples the long tail.
Your autonomous driving model hits 99% accuracy on your test set. Then a truck carrying a mirror-wrapped art installation merges onto the highway, and your perception stack has no idea what it's looking at.
An edge case in autonomous driving is a rare, unexpected scenario that falls outside the normal distribution of situations a self-driving system was trained on. Edge cases include unusual weather conditions, rare road objects, unpredictable road user behavior, and sensor failures. They represent the "long tail" of driving scenarios and are the primary safety challenge for autonomous vehicle development.
This guide breaks down what edge cases are, why they matter so much for safety, the different types you need to plan for, and practical methods for detecting and handling them. Whether you are building an L2+ ADAS system or working toward full autonomy, this is the playbook for tackling the long tail.
Key Takeaways
- Edge cases are rare driving scenarios outside a model's training distribution, and they represent the primary safety challenge for autonomous vehicle development.
- A self-driving system with 99% accuracy still faces approximately one unhandled dangerous scenario per 10,000 miles of driving.
- The four main edge case categories are environmental (weather, lighting), object-level (rare objects), behavioral (unpredictable road users), and sensor-specific (hardware failures, blindspots).
- Detection methods include rule-based filtering, data-driven anomaly detection, and active learning loops that combine model uncertainty with human expertise.
- Research from NVIDIA's Alpamayo project showed that quality reasoning annotations led to a 12% improvement in planning accuracy and a 35% reduction in close encounters.
Why Do Edge Cases Matter for Autonomous Driving Safety?
An edge case is any driving scenario that falls outside the normal distribution of situations your model was trained on. These are the rare, unusual, or unexpected events that a system encounters infrequently but must still handle correctly.
Think of it this way: the vast majority of driving is routine. Lane keeping on a clear highway. Following traffic at a signalised intersection. Parking in a well-marked lot. Your model sees thousands of hours of this kind of data and gets very good at it. But driving also includes a father chasing a ball into the street, a couch that fell off a moving truck, or a traffic cop waving you through a red light with hand signals your model has never encountered.
These are edge cases. And they matter far more than their frequency suggests.
The core challenge is what researchers call the long tail problem. In autonomous driving, the distribution of scenarios follows a power law. A small number of common scenarios account for most of your driving miles, while a vast number of rare scenarios each occur infrequently. The trouble is that safety-critical events cluster in that long tail. The scenarios your model has seen the least are often the ones where failure has the highest cost.
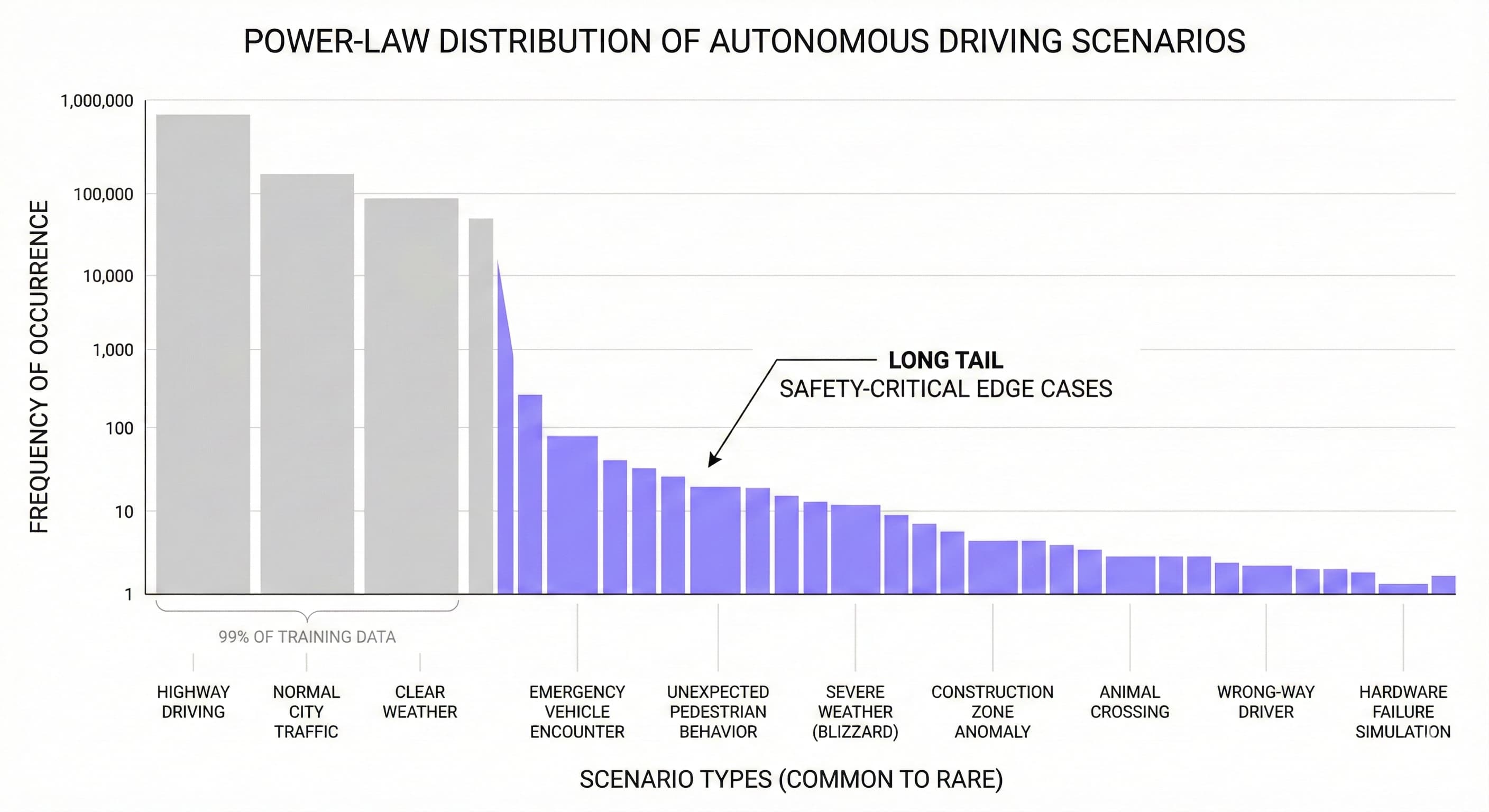
This is why 99% accuracy is not good enough. If your vehicle drives 10,000 miles and encounters 100 edge cases, a 1% failure rate means one of those edge cases goes unhandled. In autonomous driving, one unhandled edge case can be fatal.
Examples that illustrate the challenge:
- A pedestrian in a wheelchair crossing mid-block at night
- A cyclist riding the wrong way in a bike lane
- A fallen tree partially blocking your lane on a curve
- A construction zone with contradictory signage
- Sun glare reflecting off a building directly into your front-facing camera at the exact moment a pedestrian steps off the curb
Each of these is individually rare. Collectively, they represent the frontier of autonomous driving safety.
Why Edge Cases Matter for Safety
Autonomous driving is a safety-critical application. Unlike a recommendation engine that suggests the wrong movie, an autonomous vehicle that mishandles an edge case can cause serious injury or death. The margin for error is effectively zero.
This reality is reflected in evolving regulatory frameworks. ISO 21448 (SOTIF — Safety of the Intended Functionality) specifically addresses hazards that arise not from system faults but from functional insufficiencies. In plain language: your system works exactly as designed, but its design does not account for a scenario it encounters in the real world. That is an edge case problem. SOTIF requires manufacturers to systematically identify and mitigate these scenarios.
The distinction between nominal scenarios and edge cases is critical for testing and validation. Nominal scenarios prove your system works under expected conditions. Edge cases prove it does not break under unexpected ones. Both are necessary, but edge case coverage is what separates a demo from a product.
From a machine learning perspective, edge cases represent distribution shift. Your model learns a mapping from input data to driving decisions based on its training distribution. When it encounters data that looks fundamentally different, its predictions become unreliable. The model does not know what it does not know.
What Are the Main Types of Edge Cases in Autonomous Driving?
Edge cases fall into distinct types, each presenting different challenges for perception, prediction, and planning.
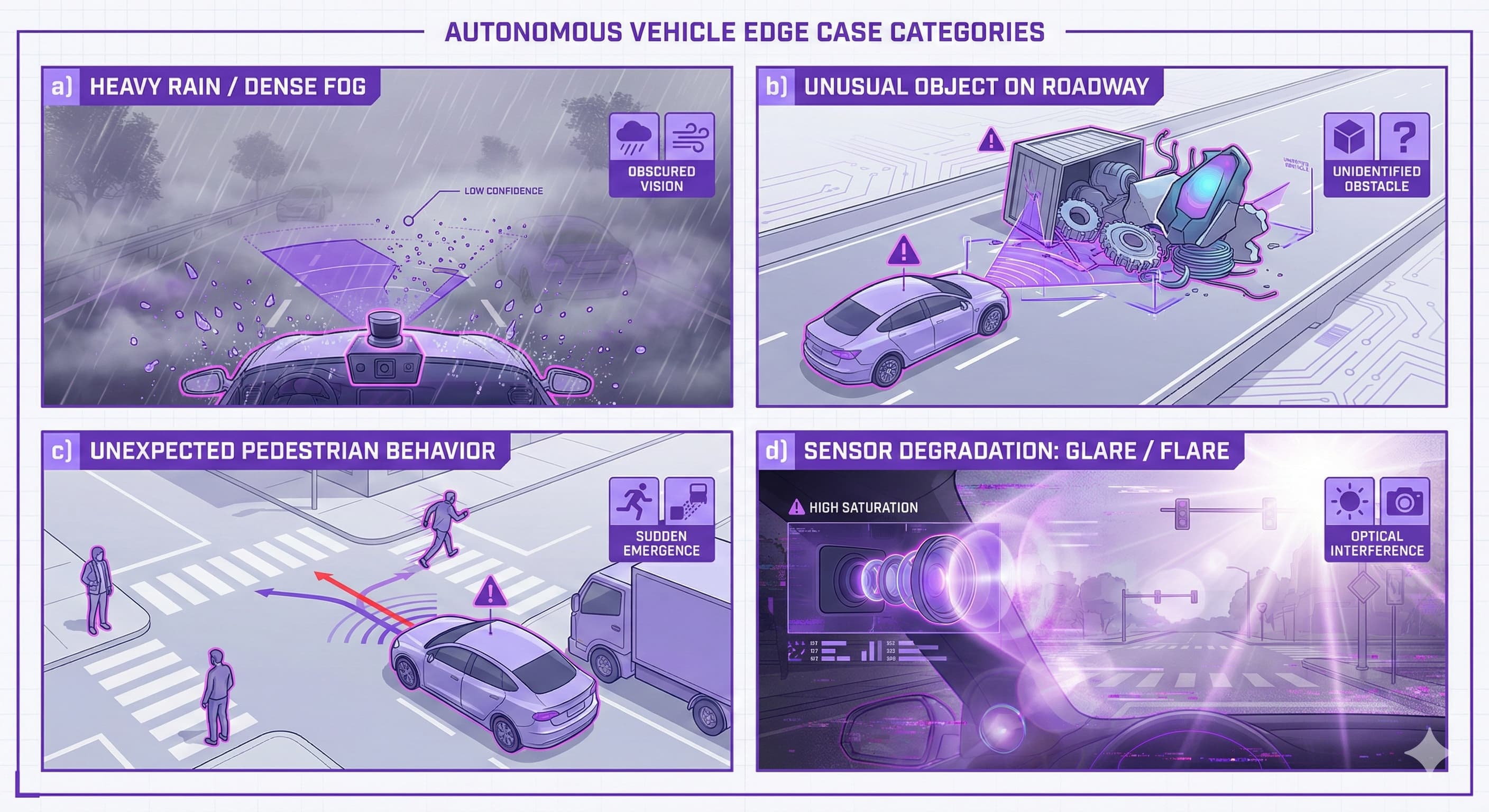
Environmental Edge Cases
The driving environment itself can create scenarios that push perception systems beyond their comfort zone.
Extreme weather is the most obvious category. Heavy rain degrades camera image quality and creates noise in LiDAR returns. Snow obscures lane markings. Dense fog dramatically reduces visibility range. But the truly difficult cases are the transitions: driving from bright sunlight into a sudden downpour, or entering a fog bank on a highway.
Unusual lighting conditions are equally challenging. Driving into or out of tunnels creates rapid exposure changes. Low-angle sun produces long shadows that can be misinterpreted as objects. Reflections off wet roads can create phantom detections.
Road surface conditions add another layer. Flooded road sections, black ice, oil spills, freshly paved surfaces with no markings, and active construction zones all change the assumptions your model makes about drivable area.
Object-Level Edge Cases
Rare objects are things your model may have never seen in training. An overturned semi-truck blocking three lanes. A mattress in the road. A horse and rider on a rural highway.
Unusual appearances of common objects are equally problematic. A vehicle wrapped in chrome. A flatbed truck carrying another car (is that one object or two?). A cyclist wearing a costume.
Ambiguous objects sit in the gray area. Is that dark shape on the road a plastic bag or a rock? Is that flash of movement a bird or a ball about to be followed by a child?
Behavioral Edge Cases
Unexpected traffic behavior includes wrong-way drivers, pedestrians jaywalking from behind parked vehicles, cyclists running red lights, and vehicles making illegal U-turns.
Cultural driving differences matter for any company deploying globally. Roundabout behavior varies dramatically between countries. The unwritten rules of merging, yielding, and right-of-way differ.
Emergency vehicles present a specific behavioral edge case. Sirens and flashing lights require specific responses that depend on local laws, direction of travel, and road geometry.
Sensor Edge Cases
LiDAR blindspots and reflections create gaps in 3D perception. Highly reflective surfaces can produce phantom points. Very dark surfaces may return no points at all.
Camera saturation and lens flare can eliminate critical visual information at the worst possible moment.
Sensor degradation over time is an operational edge case. Dirty lenses, calibration drift, and hardware aging gradually reduce system performance.
How Are Edge Cases Detected in Autonomous Driving?
Knowing that edge cases exist is one thing. Finding them systematically in petabytes of driving data is another. There are three broad families of detection methods.
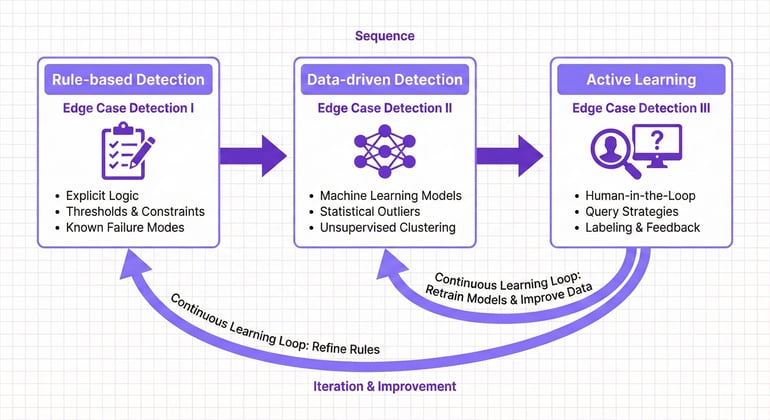
Rule-Based Detection
Scenario scripting involves writing queries against structured driving logs. For example: flag any segment where the ego vehicle brakes harder than 0.5g. Flag any segment where a detected object crosses the ego vehicle's predicted path within 2 seconds.
Threshold-based filtering extends this to continuous metrics. Flag any frame where the number of detected objects exceeds a threshold, or where tracker instability is high.
Rule-based methods are transparent and auditable. The limitation is they only find edge cases you can anticipate.
Data-Driven Detection
Anomaly detection in feature space uses the model's own learned representations to identify unusual inputs. Techniques like autoencoders, isolation forests, and density estimation can flag outliers automatically.
Out-of-distribution (OOD) detection specifically targets inputs that differ from the training distribution. Methods like Mahalanobis distance scoring and energy-based models can identify when a model is operating outside its comfort zone.
Uncertainty estimation uses the model's own confidence as a signal. Bayesian neural networks, MC-dropout, and deep ensembles all provide uncertainty estimates. High uncertainty is a strong indicator of an edge case.
Active Learning for Edge Case Discovery
The most powerful approach combines model uncertainty with human expertise in a continuous feedback loop.
Using model confidence to find hard examples means routing low-confidence predictions to human reviewers. Instead of annotating random data, you focus effort on the scenarios where the model struggles.
Feedback loops between model and annotation create a virtuous cycle. The model identifies what it does not understand. Humans annotate those scenarios. The model retrains and becomes more capable. Its uncertainty shifts to a new frontier of harder cases.
Recent research from NVIDIA's Alpamayo project demonstrates the impact: when driving models are trained with high-quality reasoning annotations, the results are significant — 12% improvement in planning accuracy, 35% reduction in close encounters, and 45% improvement in reasoning quality. These gains come not from architectural changes but from better data.
How Do You Build an Edge Case Dataset for Autonomous
Mining Real-World Driving Data
The most valuable edge cases come from real driving. Fleet data provides authentic examples of rare scenarios. The challenge is scale: you may need to process millions of miles to find a few thousand meaningful edge cases.
Simulation and Synthetic Data
Simulation can generate edge cases on demand. Modern simulation platforms can vary weather, lighting, object appearance, and behavior parametrically. The limitation is the sim-to-real gap — the best approach combines synthetic data for coverage with real data for authenticity.
Annotation Requirements for Edge Cases
Edge case annotation demands higher precision than routine labeling:
- Domain experts who understand driving safety, not just general-purpose labelers
- Sensor fusion annotation that combines camera, LiDAR, and radar for complete scene understanding
- Contextual labels that capture not just what is in the scene but why it matters
- Quality assurance workflows with multiple review stages
- Structured reasoning annotations that explain the causal chain from perception to decision
It is not enough to label what objects are present. Models need to understand why a scenario is dangerous and what the correct response is.
Kognic's Approach to Edge Case Handling
At Kognic, we have built our annotation platform specifically for the challenges that matter most in autonomous driving — and edge cases sit at the top of that list.
Platform support for complex scenario annotation. Kognic handles the full spectrum: 2D, 3D, sensor fusion, and temporal sequences. For edge cases, annotators work with the complete picture.
Active learning integration. Our platform supports active learning workflows that prioritize the most valuable data for annotation.
Quality assurance for safety-critical labels. Multi-stage review, inter-annotator agreement metrics, and configurable quality gates ensure safety-critical labels meet the required standard.
Sensor fusion for complete scene understanding. Many edge cases are only understandable when you combine multiple sensor modalities.
Language Grounding for explaining WHY edge cases are dangerous. Kognic's Language Grounding capabilities enable teams to annotate the causal reasoning behind driving decisions: what is happening, why it is dangerous, and what the correct response should be.
Edge cases are not going away. The teams that build systematic, scalable approaches to detecting, annotating, and learning from edge cases are the ones that will ship safe, reliable autonomous systems.
FAQ Section
Q: What is an edge case in autonomous driving?
An edge case is a rare or unexpected driving scenario that falls outside what a self-driving system was trained to handle. Examples include pedestrians in wheelchairs crossing at night, wrong-way cyclists, or sun glare coinciding with a pedestrian crossing. These scenarios are critical because they represent the situations most likely to cause safety failures.
Q: Why are edge cases so dangerous for self-driving cars?
Edge cases are dangerous because autonomous systems perform reliably in normal conditions but can fail unpredictably in scenarios they have not encountered before. A system with 99% accuracy still faces roughly one unhandled dangerous scenario per 10,000 miles. In safety-critical applications, even a single failure can be fatal.
Q: How many edge cases exist in autonomous driving?
The number is effectively unlimited. Edge cases follow what researchers call the "long tail problem," where rare events are individually uncommon but collectively represent a large portion of real-world risk. New edge cases emerge continuously as driving environments, vehicle types, and road user behaviors change.
Q: What is the difference between an edge case and a corner case?
An edge case is a scenario at the boundary of expected operating conditions, such as heavy fog or an unusual road object. A corner case occurs when multiple edge conditions combine simultaneously, for example, heavy fog plus a wrong-way cyclist plus sensor degradation. Corner cases are rarer and harder to anticipate because they involve compounding factors.
Q: How do companies detect edge cases in driving data?
Three main approaches exist. Rule-based methods use predefined scenario scripts and threshold filters to flag known patterns. Data-driven methods use anomaly detection, out-of-distribution detection, and uncertainty estimation to find scenarios the model struggles with. Active learning combines model uncertainty signals with human expert review to continuously identify new edge cases.
Q: What role does annotation play in handling edge cases?
Annotation is essential because edge cases require human expert judgment to label correctly. Annotators identify what is happening in the scene, classify the type of edge case, and provide contextual reasoning about why it matters. High-quality annotations with causal reasoning labels help models learn not just what objects are present, but why a scenario is dangerous.
Ready to tackle the long tail? Learn how Kognic helps autonomous driving teams build robust edge case datasets with production-grade annotation, active learning, and the quality assurance workflows that safety-critical systems demand.



.jpg)