
.jpg?width=2000&height=500&name=kognic-3d-point-cloud-annotation-banner%20(1).jpg)
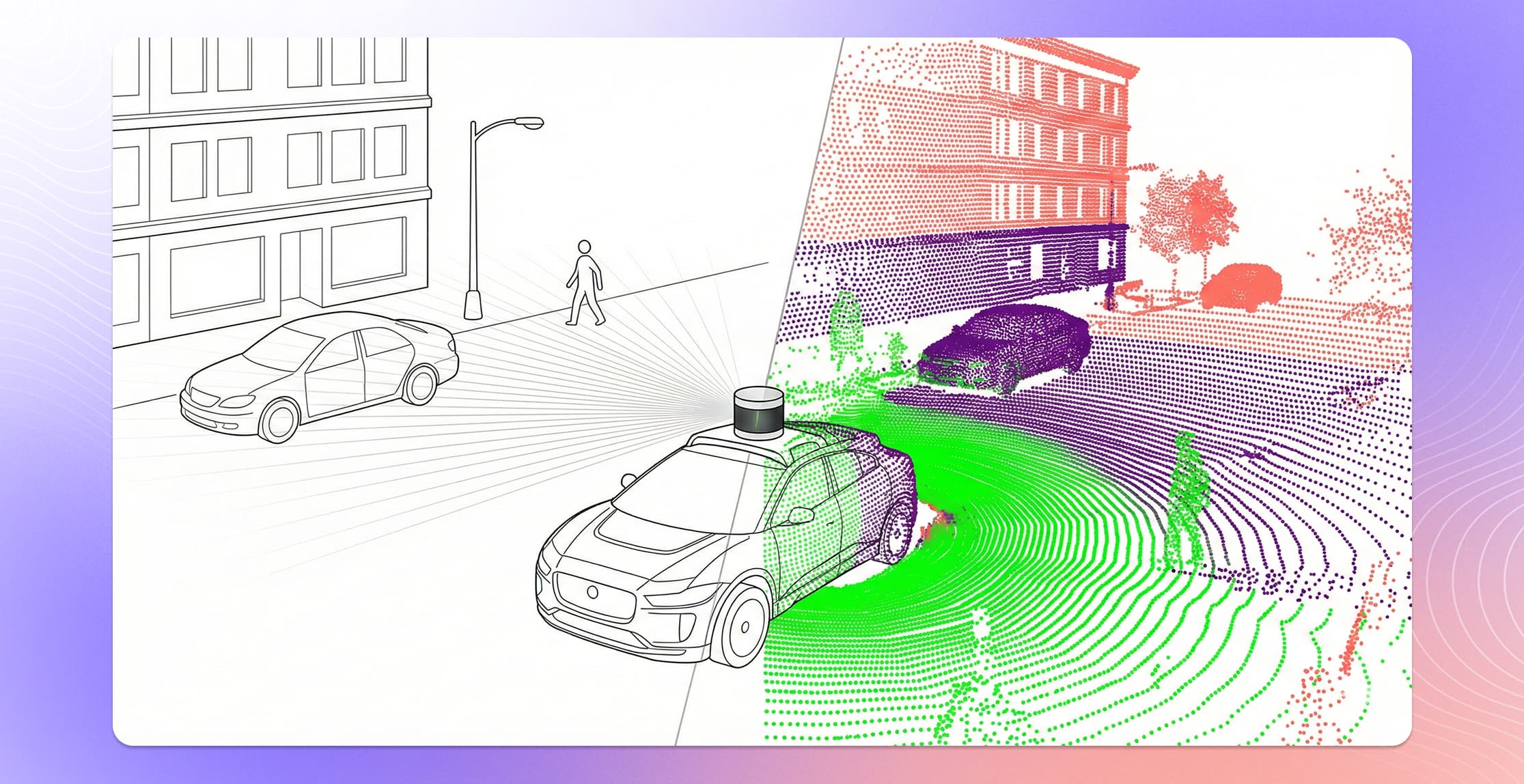
Every autonomous vehicle on the road today depends on one thing most people never see: millions of hand-labeled 3D data points that taught the vehicle's perception model what the world looks like from every angle.
That process — 3D point cloud annotation — is how teams turn raw LiDAR scans into the structured training data that self-driving systems need to detect objects, estimate distances, and make split-second driving decisions. It is also one of the most technically demanding annotation tasks in machine learning.
This guide breaks down how 3D point cloud annotation works, why it matters for autonomous driving, and what it takes to do it well at production scale.
3D point cloud annotation is the process of labeling individual points or groups of points in a three-dimensional point cloud with semantic information, such as object class, instance identity, or tracking ID. It transforms raw LiDAR or depth sensor data into structured training data that machine learning models use to understand and navigate physical environments.
Key Takeaways
- 3D point cloud annotation labels raw LiDAR data with spatial and semantic information so machine learning models can detect objects, estimate distances, and understand driving scenes.
- The five main annotation types are 3D bounding boxes (cuboids), semantic segmentation, instance segmentation, object tracking, and panoptic segmentation.
- Modern LiDAR sensors produce hundreds of thousands to millions of points per frame, making annotation at scale one of the biggest bottlenecks in autonomous driving development.
- Sensor fusion workflows, where annotators view LiDAR data alongside synchronized camera images, improve both accuracy and speed compared to annotating point clouds alone.
- The industry is shifting from pure perception annotation (what objects are where) toward reasoning data that captures causality and behavioral context for decision-making models.
3D Point Cloud Annotation in 2026
The landscape for 3D point cloud annotation has shifted significantly. Several trends are shaping how teams approach this work in 2026:
End-to-end models demand richer annotations. The industry's move toward end-to-end driving architectures means annotation requirements are expanding beyond object detection. Teams now need scene-level descriptions, reasoning annotations, and temporal context alongside traditional 3D labels.
Pre-labeling is now standard. Model-assisted annotation has moved from experimental to expected. Leading platforms integrate customer model predictions as pre-labels, with annotators refining rather than creating from scratch. Teams that aren't using pre-labeling are overspending.
Quality assurance has automated. Manual spot-checking doesn't scale to the volumes modern AV programs require. Automated quality checkers that validate cross-sensor consistency, geometry correctness, and track continuity are now table stakes for production annotation.
Consolidation is underway. Uber acquired Segments.ai. Understand.AI shut down. LiangDao filed for insolvency. The market is concentrating around platforms with the depth and sustainability to support long-term AV programs.
How are 3D point clouds generated?
A point cloud is a collection of data points in three-dimensional space. Each point has X, Y, and Z coordinates representing its position relative to the sensor, and often includes additional attributes like intensity (reflectivity) or return number.
Two primary technologies generate point clouds used in autonomous driving:
LiDAR (Light Detection and Ranging)
LiDAR sensors fire laser pulses — often hundreds of thousands per second — and measure how long each pulse takes to bounce back from objects in the environment. The result is a dense, accurate 3D representation of the scene.
Modern AV-grade LiDAR sensors produce point clouds with hundreds of thousands to millions of points per frame. A single vehicle might run multiple LiDAR units (roof-mounted, bumper-mounted, side-mounted) to eliminate blind spots, each generating its own point cloud that must be fused into a unified coordinate frame.
LiDAR point clouds are the backbone of 3D annotation for autonomous driving because they provide precise depth information that cameras alone cannot deliver.
Stereo and Depth Cameras
Stereo camera rigs can also produce point clouds by triangulating depth from paired images. While generally less precise than LiDAR at long range, stereo-derived point clouds are improving with each hardware generation and offer a lower-cost alternative for some applications.
In practice, most production autonomous driving programs use LiDAR as the primary source for 3D annotation and supplement with camera data through sensor fusion workflows.
What are the main types of 3D point cloud annotation?
Different perception tasks require different annotation types. The choice depends on what your model needs to learn.
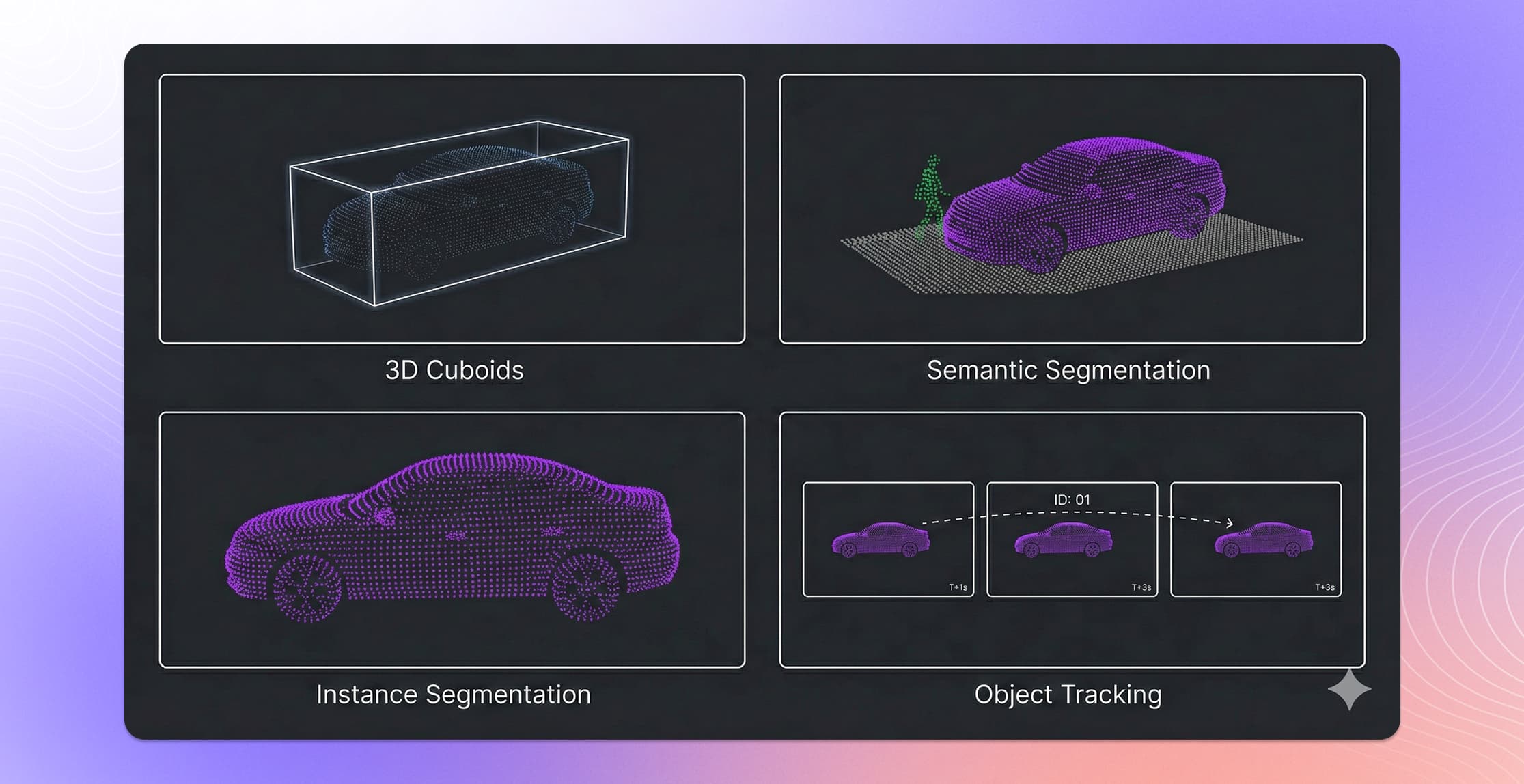
3D Bounding Boxes (Cuboids)
The most common 3D annotation type. Annotators place a rectangular box around each object of interest — vehicles, pedestrians, cyclists, traffic signs — defining its position, dimensions, and orientation in 3D space.
A single cuboid encodes:
- Position: X, Y, Z center coordinates
- Dimensions: Length, width, height
- Orientation: Heading angle (yaw), and sometimes pitch and roll
- Class label: Vehicle, pedestrian, cyclist, etc.
Cuboids are the standard for object detection training. They tell the model where things are, how big they are, and which direction they face. Getting the orientation right is critical — a car's heading determines whether it is approaching, receding, or crossing the vehicle's path.
3D Semantic Segmentation
Instead of drawing boxes around objects, semantic segmentation assigns a class label to every individual point in the cloud. The result is a fully classified 3D scene where every point belongs to a category: road surface, sidewalk, vegetation, building, vehicle, pedestrian, and so on.
This annotation type is more labor-intensive than cuboid labeling but provides richer training signal. Models trained on segmented point clouds can understand the full scene geometry, not just the locations of discrete objects.
3D Instance Segmentation
A combination of semantic segmentation and object detection. Each point is labeled with both a class (what it is) and an instance ID (which specific object it belongs to). This allows models to distinguish between individual objects of the same class — separating one pedestrian from another in a crowded scene.
3D Object Tracking
Autonomous driving data is sequential. Vehicles collect data as they move, producing frame after frame of point clouds over time. Object tracking annotation connects the same object across multiple frames by assigning consistent track IDs.
Tracking annotations teach models temporal reasoning: how fast a vehicle is moving, whether a pedestrian is about to step into the road, and how objects interact with each other over time. This is foundational for prediction and planning models.
Panoptic Segmentation
The most complete annotation type — combining semantic segmentation of background elements (road, building, sky) with instance segmentation of countable objects (each car, each person). Panoptic segmentation gives models a fully parsed understanding of every element in the scene.
Why does 3D point cloud annotation matter for autonomous driving?
Camera-based 2D annotation has been the default in computer vision for decades. But autonomous driving systems need to operate in three dimensions. A 2D bounding box on a camera image tells a model that a pedestrian exists somewhere in the frame. A 3D cuboid in a point cloud tells the model exactly how far away that pedestrian is, how tall they are, and which direction they are moving.
That difference is the difference between a model that recognizes objects and a model that can make safe driving decisions.
Depth accuracy. LiDAR-derived point clouds provide centimeter-level distance measurements. This precision propagates directly into model performance — particularly for safety-critical tasks like collision avoidance and path planning where knowing an object is 15 meters away versus 18 meters away determines whether the vehicle brakes or continues.
360-degree coverage. Unlike cameras with fixed fields of view, multi-LiDAR setups provide full surround coverage. Annotating complete point clouds trains models to understand the environment in every direction, not just what is directly ahead.
Sensor fusion foundation. Most production perception stacks fuse LiDAR and camera data. Accurate 3D annotations serve as the ground truth for training and validating these fusion models, ensuring that the 3D cuboid in the point cloud aligns precisely with the 2D detection in the camera image.
What are the biggest challenges in 3D point cloud annotation?
3D annotation is significantly harder than 2D image labeling. The challenges are both technical and operational.
Point Cloud Density and Sparsity
LiDAR point clouds are inherently sparse compared to camera images. Objects at distance may be represented by only a handful of points, making it difficult for annotators to determine object boundaries, class, and orientation. A pedestrian 80 meters away might appear as a cluster of 10-20 points — enough for an experienced annotator to identify, but far harder to label precisely than the same pedestrian in a high-resolution camera image.
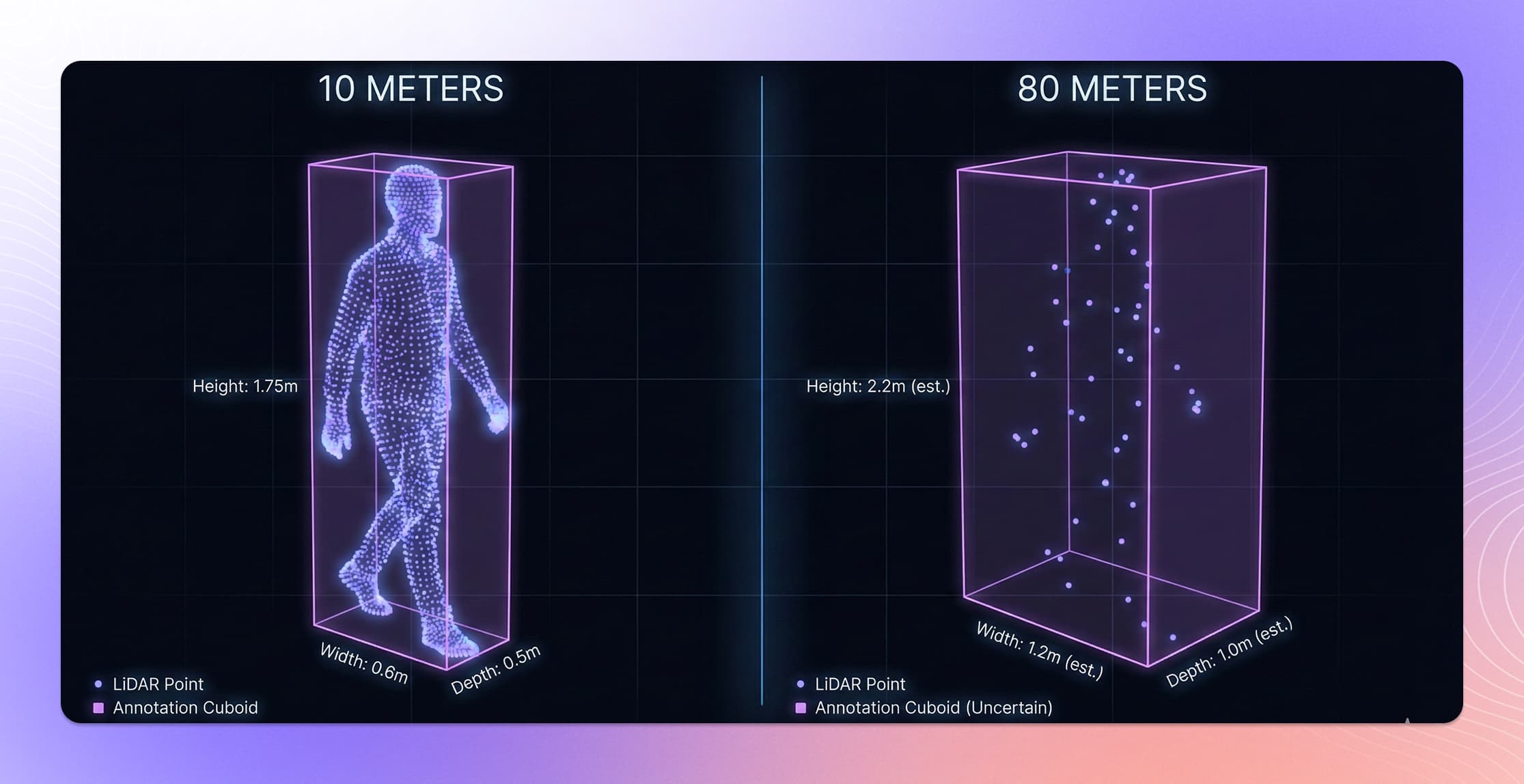
Different LiDAR sensors also produce dramatically different point densities. A 128-channel LiDAR generates much denser clouds than a 32-channel unit, and annotation workflows need to handle both.
Occlusion
Objects in real driving scenes frequently occlude each other. A parked truck may hide a pedestrian stepping into the road. A bus may block the view of an intersection. Annotators must decide whether to label partially visible objects and, if so, how to estimate the full extent of occluded portions. Consistent handling of occlusion is one of the hardest parts of building annotation guidelines.
Scale and Throughput
Production autonomous driving programs generate enormous volumes of point cloud data. A single test vehicle driving for one hour may produce tens of thousands of frames, each requiring annotation. Multiply that by a fleet of test vehicles across multiple cities and weather conditions, and the annotation volume becomes staggering.
Maintaining quality at this scale requires purpose-built tooling, structured workflows, and experienced annotation teams — not just a labeling interface and a large crowd of annotators.
Annotation Consistency
3D cuboid placement is inherently more subjective than 2D bounding boxes. Two annotators may place a cuboid around the same vehicle with slightly different positions, dimensions, or heading angles. Over millions of annotations, these inconsistencies compound and degrade model performance.
Achieving consistency requires detailed annotation guidelines, automated quality checks, and calibration processes that align annotator behavior across the entire workforce.
Multi-Frame Temporal Alignment
For tracking annotations, objects must be consistently identified across sequential frames even as they move, change appearance (due to changing viewing angle), or temporarily disappear behind occlusions. Temporal consistency is critical for training prediction models but adds a layer of complexity that frame-by-frame annotation does not require.
Best 3D Point Cloud Annotation Tools (2026)
Choosing the right tool for 3D point cloud annotation depends on your data complexity, team size, and whether you need a platform, a service, or both. Here's how the leading options compare for autonomous driving use cases.
Kognic
Best for: Production-scale autonomous driving annotation with sensor fusion.
Kognic is purpose-built for autonomous driving. The platform handles multi-sensor fusion natively, displaying synchronized camera, LiDAR, and radar views in a unified annotation interface. Annotators create 3D cuboids, semantic segmentation masks, and track IDs that project automatically across all sensor views.
Key differentiators: over 90 automated quality checker applications designed for driving data, pre-labeling integration that saves up to 68% of annotation time, and a trained workforce of 4,000+ AV-specialist annotators. Kognic has delivered over 100 million annotations to OEMs and Tier 1 suppliers.
Deployment: Managed service, platform license, or hybrid.
Certifications: TISAX Level 3, ISO 27001.
CVAT (Open Source)
Best for: Research teams, academic projects, and teams with engineering resources to self-host.
CVAT (Computer Vision Annotation Tool), originally developed by Intel, supports basic 3D cuboid annotation in point clouds. It's free and open source, making it accessible for experimentation and smaller projects. However, 3D support was added on top of a 2D-first architecture, which limits performance with dense point clouds and long sequences.
Limitations: No native sensor fusion. Limited automation for 3D tasks. No managed annotation workforce. Quality assurance requires custom tooling.
BasicAI
Best for: Smaller teams needing affordable 3D annotation with some automation.
BasicAI offers a cloud-based platform that supports LiDAR point cloud annotation with AI-assisted pre-labeling. The platform handles datasets up to 150 million points and claims 82x faster annotation speeds compared to fully manual methods. It provides a free tier for smaller projects.
Limitations: Less mature for complex multi-sensor fusion. No annotation services or AV-specialist workforce. Quality assurance tooling is more generic.
Segments.ai (now part of Uber)
Best for: R&D-stage teams building early perception models.
Segments.ai focuses on point cloud labeling ergonomics: quick cuboid creation, smooth instance segmentation, and slice views for dense scenes. The interface is designed for speed on repetitive street-scene tasks. Acquired by Uber in 2025 to power Uber AI Solutions.
Limitations: Primarily a labeling tool, not a full annotation operations platform. Limited quality assurance depth for production volumes.
Encord
Best for: Teams that need annotation plus data curation in one platform.
Encord combines annotation, data curation, and evaluation in a single platform. Their Physical AI Suite (launched 2025) added multi-sensor support for camera, LiDAR, and radar. Strong on data management and workflow governance.
Limitations: 3D and sensor fusion capabilities are more recent additions, not the core focus since founding. Software-only, no annotation workforce. One named AV customer.
Comparison Summary
| Feature | Kognic | CVAT | BasicAI | Segments.ai | Encord |
|---|---|---|---|---|---|
| Primary focus | Autonomous driving | General CV | General 3D | Robotics/AV R&D | Multi-industry AI |
| Sensor fusion | Native (camera + LiDAR + radar) | No | Basic | Basic | Recent addition |
| 3D maturity | 7+ years production | Basic cuboids | Growing | Good for R&D | Recent |
| Quality automation | 90+ AV-specific checkers | Manual/custom | Generic QA | Basic | Automated agents |
| Annotation services | 4,000+ AV specialists | No | No | No | No |
| Pre-labeling | Full integration + 68% time savings | Limited | AI-assisted | Propagation | SAM2-based |
| Pricing | Enterprise | Free (open source) | Free tier available | Per-seat | Per-seat |
| AV certifications | TISAX L3, ISO 27001 | None | None | None | SOC 2 |
The right choice depends on your stage. Research teams experimenting with point clouds may start with CVAT or BasicAI. Teams moving to production-grade annotation for autonomous driving need the depth of quality assurance, sensor fusion, and domain expertise that a specialized platform provides.
What are best practices for production-grade 3D annotation?
Teams that deliver reliable 3D annotation at scale tend to follow similar patterns.
Start with Clear Annotation Guidelines
Define exactly how annotators should handle ambiguous situations before labeling begins. How tight should cuboids be? How do you handle partially visible objects? What is the minimum number of points required to label an object? These decisions shape data quality more than any tooling choice.
Use Sensor Fusion Workflows
Annotating point clouds in isolation is harder and less accurate than annotating with synchronized camera views alongside the 3D data. When annotators can cross-reference what they see in the point cloud with corresponding camera images, accuracy improves — especially for object classification and orientation estimation. Kognic's platform supports native multi-sensor annotation with calibrated views across LiDAR, camera, and radar.
Invest in Pre-labeling and Automation
Model-assisted pre-labels — where an existing model generates initial annotations that human annotators then review and correct — can reduce annotation time by up to 68%. Pre-labeling is particularly effective for cuboid placement and tracking, where the model handles the repetitive spatial estimation and humans focus on edge cases and quality assurance.
Build Quality Into the Workflow
Quality cannot be an afterthought or a final inspection step. The most reliable annotation programs embed quality checks throughout the workflow: automated geometric validation (are cuboids physically plausible?), cross-frame consistency checks (do track IDs remain stable?), and statistical monitoring of annotator performance over time.
Kognic, for example, runs 90+ automated quality checker applications that catch domain-specific errors before they reach your training pipeline — cuboid orientations that violate physics, labels that drift across frames, and dozens of other AV-specific quality rules.
Plan for Iteration
Annotation guidelines evolve. Model architectures change. New object classes get added. Production annotation is not a one-time task — it is an ongoing process that must adapt as your models and requirements mature. Choose partners and tooling that support guideline versioning, re-annotation workflows, and flexible project configuration.
FAQ Section
Q: What is the difference between 3D point cloud annotation and 2D image annotation?
3D point cloud annotation labels data in three-dimensional space (X, Y, Z coordinates), capturing depth and spatial relationships that 2D images cannot represent. This makes it essential for applications like autonomous driving, where a vehicle needs to know not just what an object is but exactly how far away it is and how much space it occupies.
Q: How long does it take to annotate a 3D point cloud frame?
A single 3D point cloud frame typically takes 6 to 10 times longer to annotate than a 2D image, depending on scene complexity and annotation type. Cuboid annotation is faster than full semantic segmentation. Pre-labeling with model-assisted tools can reduce annotation time significantly, with some teams reporting up to 68% time savings.
Q: What is the most common type of 3D point cloud annotation?
3D bounding boxes (cuboids) are the most widely used annotation type. A cuboid encodes an object's position (X, Y, Z), dimensions (length, width, height), orientation (heading angle), and class label. This format is the standard input for most 3D object detection models used in autonomous driving.
Q: Why is sensor fusion important for 3D annotation?
Annotating point clouds in isolation is harder because LiDAR data has gaps. Glass, thin poles, and distant objects may return very few points. When annotators can cross-reference the point cloud with synchronized camera images, they can verify object classes and boundaries more accurately. This multi-sensor approach reduces errors and speeds up the workflow.
Q: What is panoptic segmentation in 3D point clouds?
Panoptic segmentation combines semantic segmentation (labeling every point with a class) and instance segmentation (distinguishing between individual objects of the same class). It produces a complete scene understanding where every point is classified and every distinct object is identified separately.
Q: How many annotated frames do autonomous driving models need?
Production-grade autonomous driving models typically require millions of annotated frames to achieve reliable performance. The exact number depends on the operational domain, the number of object classes, and the diversity of driving scenarios (weather, lighting, road types) the model needs to handle.
How is 3D annotation evolving beyond object perception?
The autonomous driving industry is in the middle of a fundamental shift. Traditional perception models ask: what is in the scene? Next-generation vision-language models ask: why are things happening, and what should the vehicle do about it?
This shift is changing what annotation data looks like. Beyond labeling objects with cuboids and class labels, teams are beginning to annotate reasoning traces — structured descriptions of causal relationships, driving decisions, and behavioral predictions. A pedestrian is not just a labeled cuboid. The annotation captures that the pedestrian is looking at their phone, has not noticed the approaching vehicle, and is likely to step off the curb.
This evolution from what to why is where Language Grounding capabilities come in — adding structured text annotations to 3D scenes so that models learn to reason about driving situations, not just recognize objects in them.
3D point cloud annotation remains the foundation. But the most forward-looking teams are already building on that foundation with reasoning data that will power the next generation of autonomous driving models.
Kognic's platform is built specifically for 3D point cloud annotation in autonomous driving. With native sensor fusion, 90+ automated quality checkers, and a trained workforce of AV specialists, Kognic delivers the annotation quality your perception models need.
- Explore the platform: See how Kognic handles 3D annotation
- Read more: Sensor Fusion Annotation
- Read more: Camera vs LiDAR Annotation
- Get in touch: Request a demo with your own data



.jpg)