The Long Tail and the Fleet Data Deluge
I visited China a few weeks ago, and a statement from Momenta at AutoSense really stuck with me. To paraphrase: "In order to close the long tail of rare events and scenarios, you need to leverage your fleet-collected data."
On the surface, "we need more data" is the classic mantra of the Machine Learning engineer. But the implications of applying this to production fleets are massive. Most AD/ADAS companies currently rely on data collection/test fleets of 10s or 100s of vehicles. But consider a manufacturer like Mercedes-Benz, which sold 2.4 million vehicles last year. When you move from a collection fleet to a customer fleet, the data volume doesn't just grow; it explodes. To leverage this scale and close the long tail of rare events, you cannot just collect data; you need to find the pieces of gold, and to do so, you must ruthlessly curate it.
The Standard Pipeline (and where it breaks)
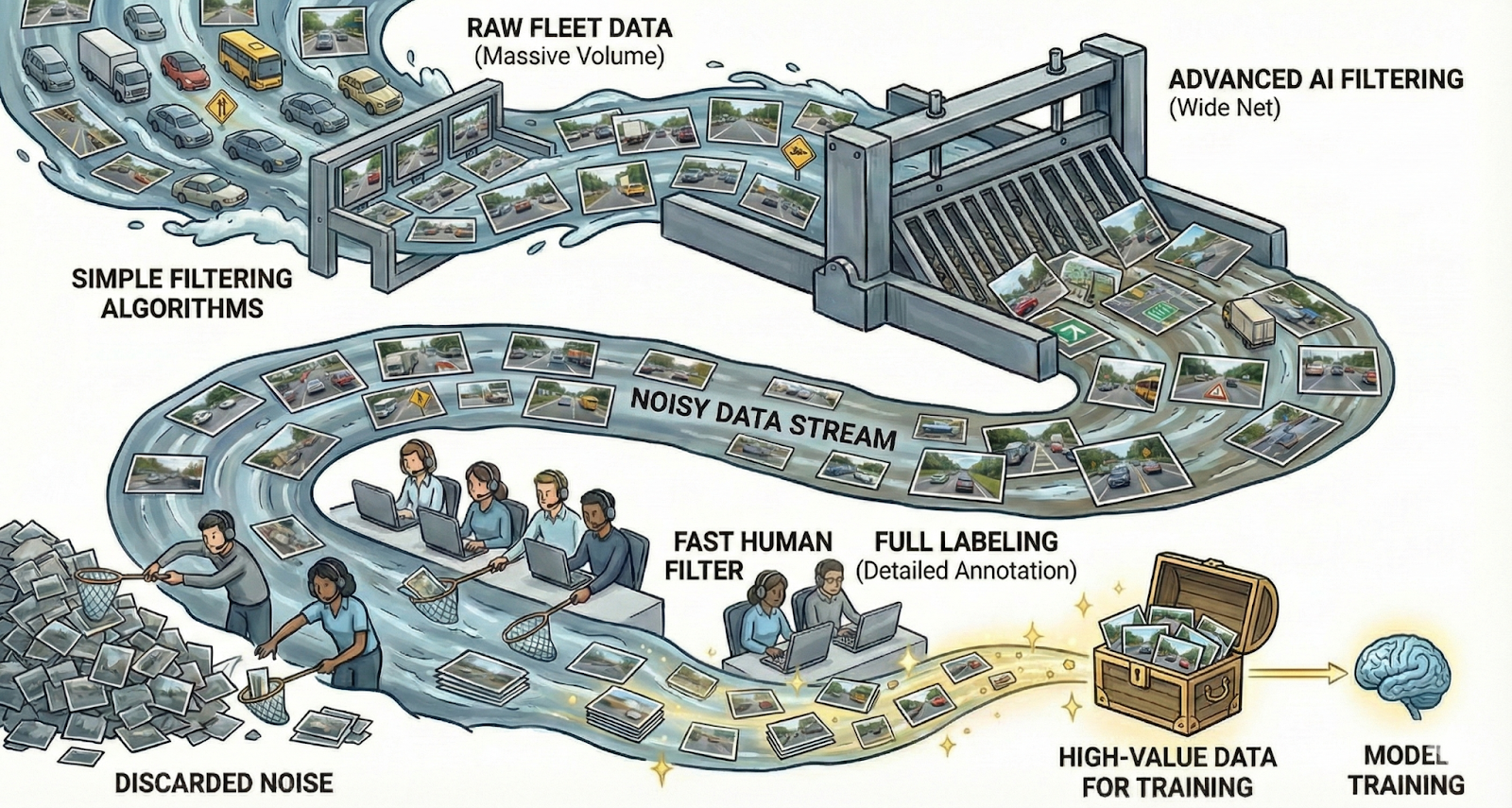
Most industry-standard curation pipelines follow a similar logic:
- In-Vehicle: Triggers capture interesting scenarios (such as hard braking and heavy steering) and upload them to the cloud.
- Cloud Filtering: Metadata filters (location, weather) and heavy offline stacks (VLMs, offline perception) attempt to automatically detect specific events.
- Labelling: "Interesting" scenarios are sent for full, pixel-perfect annotation.
- Training: New data is used to improve performance.
The industry has spent the last year trying to optimise Step 2. The assumption is that better AI filtering (like running a Vision Language Model) will solve the volume problem.
However, there is a trap: Automated selection algorithms are prone to noise.
Commonly, teams use a "Top N" approach, ranking data based on similarity to a prompt. This works for simple concepts ("A red truck"), but it fails on the complex compositional queries required for the long tail.
For example, if you query for: “A crossing where the traffic light just turns green for vehicles AND a pedestrian starts to cross the road too late," a standard VLM similarity search query will often return hits and many results in top N match parts of the prompt. You get plenty of green lights and plenty of pedestrians, but very few examples where both happen simultaneously.
The result? You send noise to your expensive labelling pipeline, wasting budget on data that doesn't actually improve the model.
The Case for Human Selection
What we have learned over the last year is that being more selective before labelling yields massive ROI.
Instead of trusting the "Top N" algorithm blindly, we introduce a Fast Human Filter.
This is a high-throughput, straightforward annotation task in which annotators answer a few binary questions about the pre-selected data. This allows us to cast a much wider net at the algorithmic level (Step 2), knowing that a human will quickly discard the false positives (the "green light but no pedestrian" cases) so that you find as many critical scenarios before they hit the expensive labelling queue.
This improves the feedback signal in two ways:
- Purity: Your model trains only on the exact scenarios you intended.
- Cost: You will not pay to label a scenario that turned out to be irrelevant.
The Expert Loop
This human-in-the-loop approach becomes even more critical as ADAS systems mature. We are moving from "what is in the image?" to "why did the system fail?"
Defining a "safety-critical scenario" is often too nuanced for an automated query. Was the driver takeover a reaction to a system failure, or was it simply a case of nervous driving? What does a "near-miss" actually look like in this specific ODD?
These aren't just labeling tasks; they are forensic questions. By inserting domain experts into the selection loop, you can capture scenarios that explicit code queries would miss, ensuring you aren't just training on what you know to look for, but what you need to fix.
Summary
Fleet-scale data only creates value if you can separate signal from noise. Algorithmic “Top N” filtering alone won’t close the long tail, it produces too many false positives and burns your labeling budget.
The solution is simple and proven: Combine broad automated filtering with fast human validation, and add expert review where nuance matters.
Do this and you get:
- Cleaner, more targeted training data
- Lower labeling cost
- Faster iteration on real failure modes