

Kognic was founded in 2018 with a primary focus on helping machines "see" the world through data - as we strive for automated and autonomous driving . As with many early stage startups, finding product market fit to grow the business was step one. To be able to iterate fast without knowing our domains, the code base was one big monolith developed by small functional teams, namely a backend team, a frontend team and a machine learning team.
As the business started to grow, so did the size of the team and the codebase. As with any change of circumstances, a new set of problems arise. For the engineering team at Kognic, the consequences of a growing team were inefficient collaboration which resulted in difficulties in synchronizing feature prioritization between functional teams.
The previous high engineering velocity started to decrease, something had to be changed.
In an attempt to solve these problems, the engineering teams at Kognic re-organised into cross-functional teams responsible for the entire product development process with infrastructure assistance from platform enablement teams. The initial cross-functional teams were small with 3-4 developers in each team and often only one developer per functional area. The main purpose of these cross-functional teams was to get a clearer focus on the features rather than the tech, by having a complete set of skills within the team to take a feature from start to finish.
As things started to stabilize with respect to feature ownership, the cross-functional teams grew, typically by adding 1-3 developers per team and more often than not, each team had multiple developers per functional area. This created collaboration issues within the teams. Being more than one developer per functional area within the cross-functional team resulted in merge conflicts, disagreement about how code should be structured and a lot of time was spent trying to understand each other's pull requests.
We also saw collaboration issues between cross-functional teams. The codebase was still monolithic, entangled and lacked test coverage. Developers that are uncertain about hidden side effects and possible error propagation to other teams/domains is a horrible scenario which results in lowered engineering velocity and increased number of bugs in production.
The lack of tests was both due to quick growth but also because the code was difficult to test. Another aspect that slowed down productivity was the fact we had a single code repository. This meant that we had long build times before we could deploy/test and if the code got into a broken state it meant that a lot of people were affected.
The problems we saw in our newly formed cross-functional team can be summarized in the following bullets
- Our entangled monolithic codebase led to unclear ownership boundaries and frequent cross-team discussions. How can we make a clear distinction of what belongs to a specific cross-functional team?
- Developers didn't feel confident making code changes or product increments due to an entangled codebase with hidden side effects, low test coverage and possible error propagation to other teams/domains.
- The business logic of an application could be located anywhere within the codebase and was spread out between all layers (api, database integrations, etc.) of the application. How could we improve the structure of our codebase?
- It was hard to collaborate within the same feature/domain as developers organized code and logic differently. How could we make sure that we had a unified and agreed upon way of writing code?
Again, something had to be done to change the situation. Engineering velocity is key in a high growth environment.
Splitting The Monolith Into Feature Domains
In order to improve the situation we started reading about microservice architecture and design principles. We found a design pattern called The Bounded Context that felt very applicable to what we wanted.
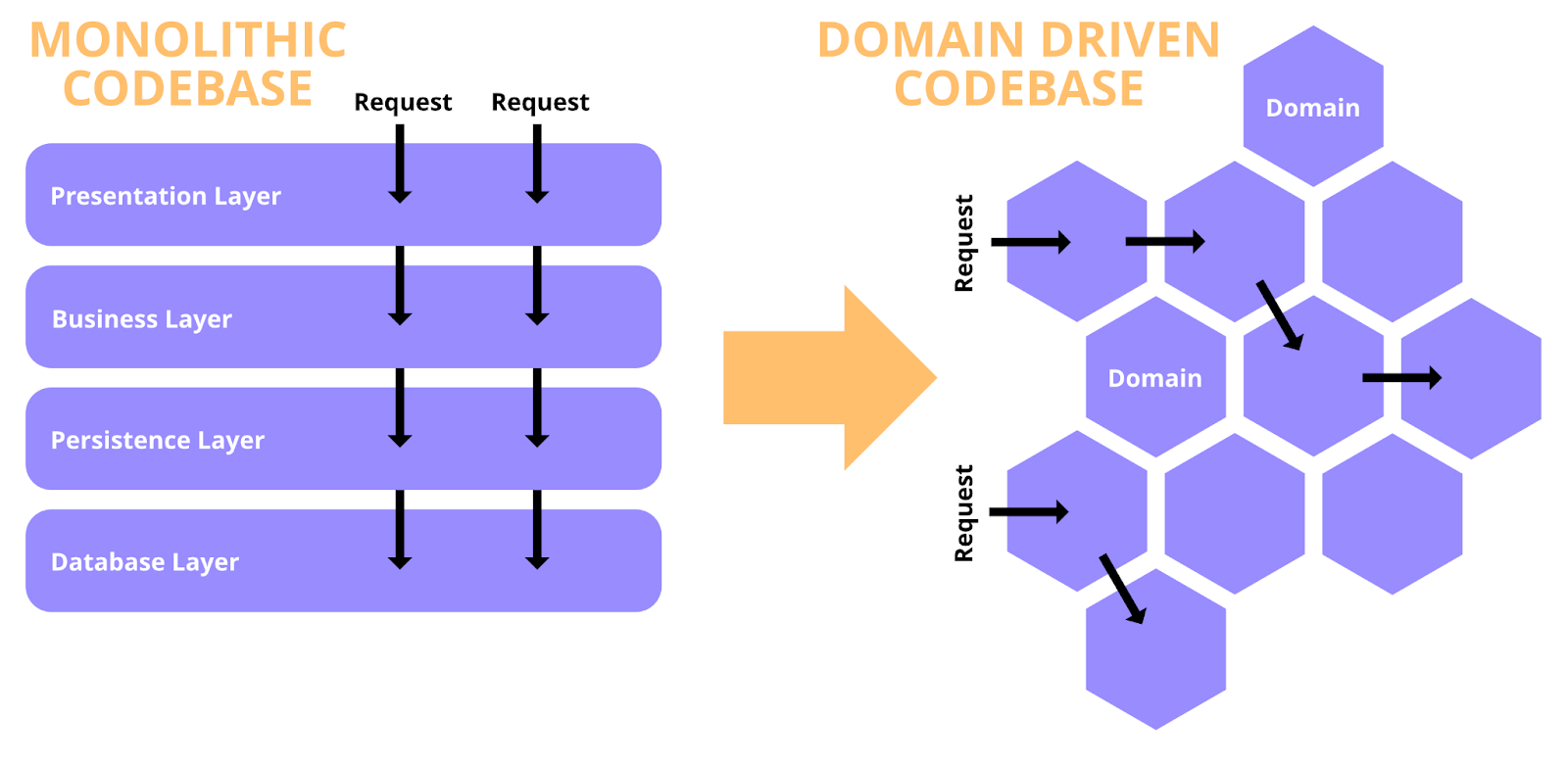
The Feature Domain and Its Bounded Context
A domain should be seen as a bounded context in a larger product. In other words, an isolated island in a collection of islands that together creates a bigger picture. A bounded context can be described as an agreed-upon vocabulary describing the domain’s products, entities, user flows and actions that can be performed on the products. It should have a clear purpose, but still be large enough in order to be independent.
If we look at an e-commerce company building their own website you might for example find the following domains:
- Product Inventory
- Product Browsing
- Shopping Carts and Checkout
- Order Management
- Account Management
They all have a purpose, their own data state and clearly defined boundaries on how to interact with them.
But what do we mean by independent domains?
A domain will most likely not be fully independent, it will probably need to communicate or share information with other domains, but it’s important to architect these inter domain dependencies (aka “boundaries”) in a way so that the domain has a clear ownership (write access) of its own data. A clear boundary consists of a clear contract specifying what can enter and what can leave the context. This contract will ensure that the domain remains independent.
What new problems arised by splitting the monolith apart?
There will almost always be at least some need to get data from other domains. This became very clear as soon as we had started the work of splitting the monolith. To do this in an effective way, we needed another set of tools to take on these challenges.
Communication Between Domains
“Splitting the monolithic codebase apart into domains in all glory, but how about the downsides? How do we share data? How do we trigger a side-effect in another domain?”
Let’s take a look at the e-commerce example again; The Shopping Carts and Checkout domain should probably present a summary of the shopping cart before you decide to move on with your checkout. On its own, the shopping cart only knows about the item’s unique identifier, no further details such as an item’s name, description, color or size. In order to please the customer and present these details the domain would need to access the Product Inventory domain’s data.
After a successful checkout, the domain also needs to, by triggering a side-effect, inform the Order Management domain about this. Otherwise, the order will neither be created nor handled.
Sharing Data
Using HTTP requests
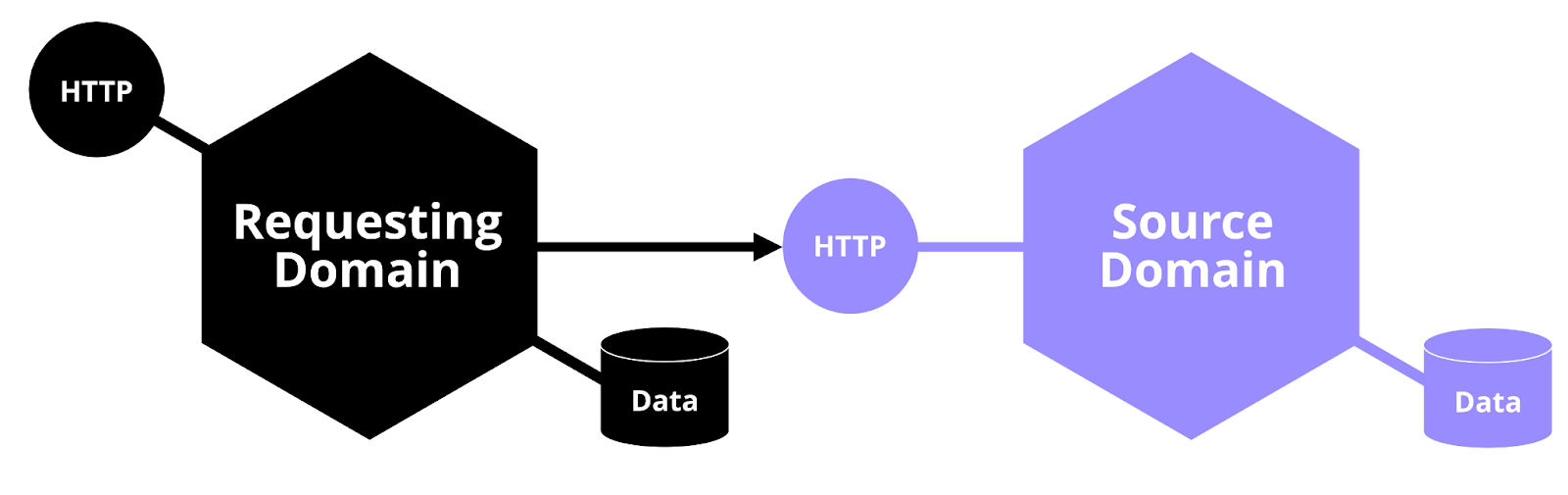
Our first way of fetching data from other domains was to call them with a simple HTTP request. Most domains already had an API up and running and we would only be tasked with adding a specific route for our use case. This was an easy out of the box solution to start out with when the need for fetching data between our newly separated domains arised. Usually the client code, for communicating with the provided routes, is located as a separate package in the source domain. The subscribing domain can fetch the data just as easily as a method call by adding a dependency to the client package in the source domain.
Pros:
- Easy to set up.
- Agnostic to language used.
Cons:
- Could potentially add a lot of load on the source domain if complex data retrieval is triggered or if usage is unexpectedly high.
- Our experience with fetching data through HTTP requests from source domains usually results in very specific implementations that rarely generalize well for new use cases.
Using change data capture
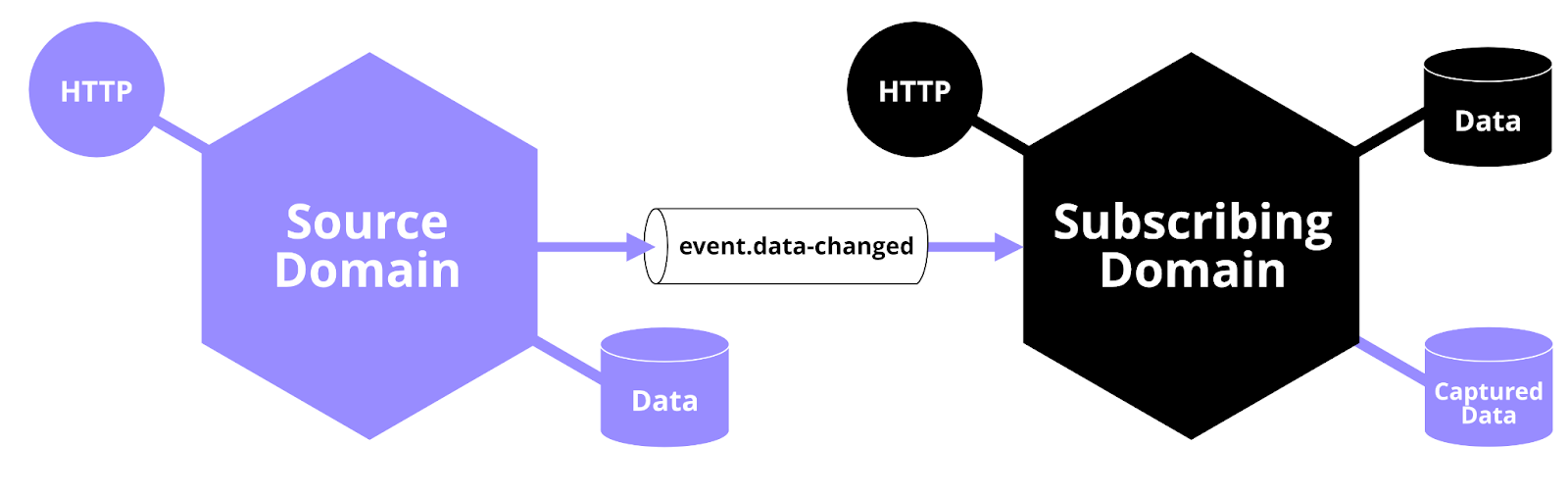
Another way of solving the problem of acquiring data from other domains, that we later discovered, was the concept of Change Data Capture (CDC). Let’s take another look at the e-commerce example above. More specifically the challenge of obtaining the extra contextual information (name, size, color, etc.) about the items located in the Product Inventory (source domain).
Whenever an item is added, updated or deleted in the Product Inventory an event is sent out on a message queue and any other domains can subscribe to these events and store that information in a local copy. This requires the source domain to publish events at all entry points where items can be changed. It also needs to provide a CDC package with table declarations and code for a data capturer that stores the event data.
Pros:
- Very fast response time for the subscribing domain application since the data is stored in a local database.
- Predictable response time compared to HTTP requests.
- No load introduced on the source domain.
- A future proofed interface that requires minimal changes when new use cases are found.
Cons:
- Needs more coding effort compared to the HTTP calls. Especially if multiple entities need to be provided.
- For very large amounts of data, CDC is probably not a good option due to duplication and slow backfill to new subscribers.
- Rarely needs much changes, but if a change is required it would entail a significant effort. E.g. backfill and db migrations in multiple subscribing domains.
As you might have observed HTTP calls and CDC are in many ways its own opposites. The former is easy to set up but might introduce issues as the company and its teams grow. The latter needs more code and infrastructure, but scales very well if the load on the domain increases a lot. If our use case requires large amounts of data HTTP would be the preferred option.
Trigger Side Effects
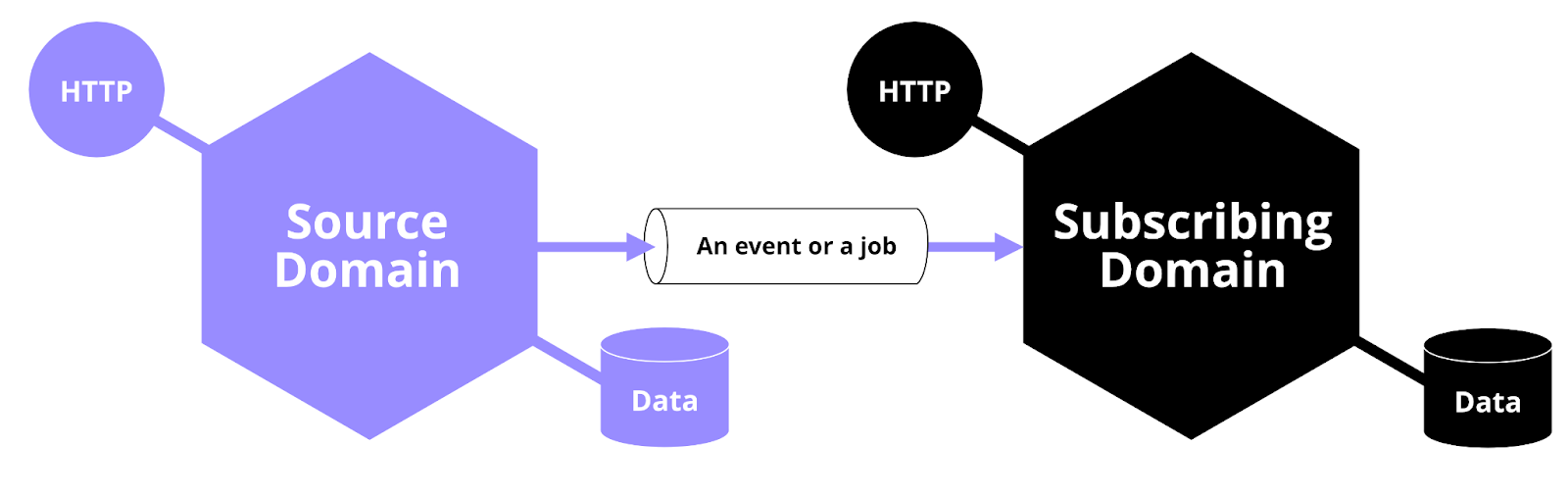
We have talked a lot about reading data from other domains and keeping the domains separated, but sometimes you might also want to trigger side effects in other domains when something happens with an entity. We have handled this in a very similar way as how the CDC concept is implemented above. Instead of implementing a fully fledged data capturer with storing capabilities, we implement a listener that just listens for a message, either an event or a job, to be done and then triggers the desired side effects.
Internal Feature Domain Structure
“The business logic of an application could be located anywhere within the codebase and was spread out between all layers (api, database integrations, etc.) of the application. How could we improve the structure of our codebase?”
“It was hard to collaborate within the same feature/domain as developers organized code and logic differently. How could we make sure that we had a unified and agreed upon way of writing code?”
Getting the domains separated helped us a great deal in easing the cooperation between teams, yet we still lacked a good way of structuring our codebase to ease the cooperation within the domain.
For example, the business logic could be located anywhere and was often spread out between all layers of the application. This made it difficult to understand and it was also hard to test the business logic in a good way.
Luckily, we found a pattern called Hexagonal Architecture, also referred to as Ports and Adapters, that is both a good fit for structuring independent domains and also for having a clear way of structuring the internals within a domain. Similar patterns exist such as the Onion Architecture and the Clean Architecture.
Hexagonal Architecture
The idea of the Hexagonal Architecture is to create an abstraction layer that protects the core of an application, i.e. the business logic and entities, from external tools and technologies. Any interaction with external tools and technologies goes through a defined interface describing what can enter or leave the application. External tools and technologies, also referred to as adapters, can then in a controlled way implement or interact with the interfaces, also referred to as ports.
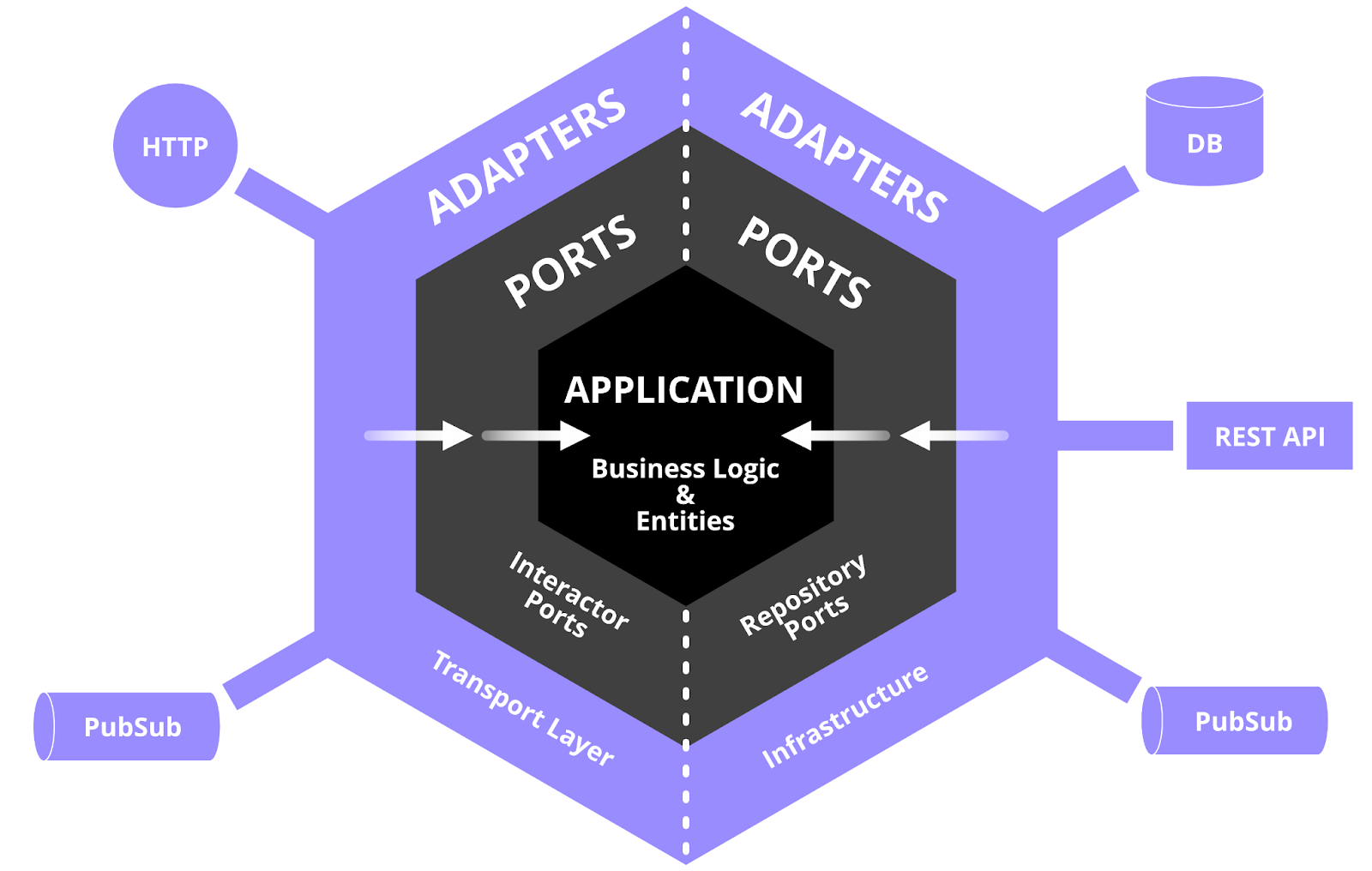
An overview of the dependencies between the different components within the hexagonal domain. The arrows illustrate that adapters depend on ports and that ports depend on the application.
For example, an application could be exposed by a REST API adapter and talk to a Postgres database adapter, but the main advantage is that the application is technology-agnostic and does not care how the ports are implemented.
By keeping the application loosely coupled to the external world it’s a lot easier to test and it also helps a great deal for getting a good understanding of how to structure the codebase.
The components of a hexagonal domain
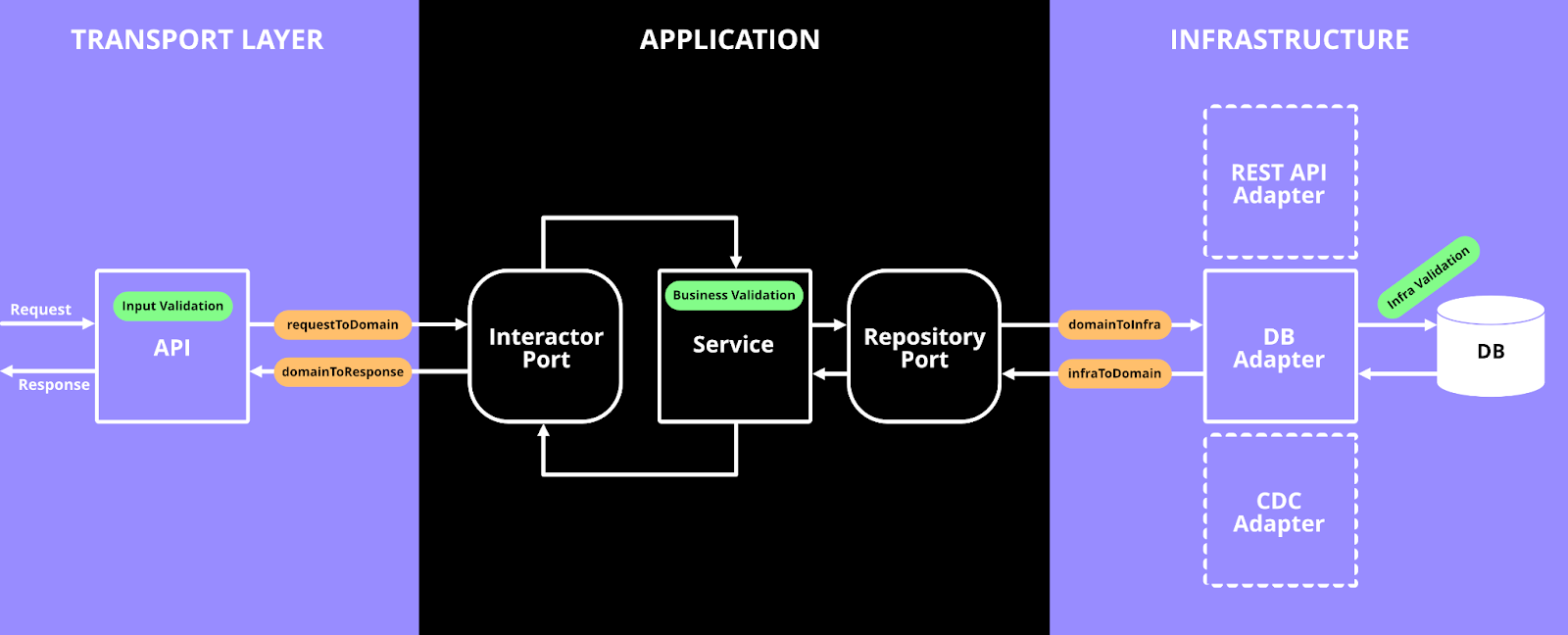
Data flow between the components in a Hexagonal Architecture
Application - Services & Entities
This is the core component where all the business logic and domain entities are defined. This component has no dependencies on any other components.
All incoming interactions through an interactor port are handled by a service implementing the port interface. This is where all the business logic goes. To store and fetch data, the service makes use of the contracts specified in the repository ports. Therefore, it should be possible to use any kind of implementation of the repository ports. Since this is the business logic heavy part, this is where most of the testing needs to be done. Any interaction with for example a specific type of storage (adapter) is usually mocked while testing.
All domain models (e.g. users, orders etc) that are used by the application core component are referred to as entities. Entities are used by services and the interface contracts defined in the ports component.
Ports
This component contains all the contracts between the application and the surrounding adapters (transport layer and infrastructure). They specify the boundary of the application, i.e. what could enter and what could leave. Unlike the adapters the port does not specify how the contract is implemented, e.g. what type of data storage is used.
Adapters
Adapters are the component that implements the ports. These implementations could for example be an API (transport layer) that serves as the interface to the outside world or it could contain code for persisting data in a database (infrastructure). This component should preferably not contain any business logic and therefore only implement very basic operations. There could be multiple adapters per port, for example one adapter implementation could be used for testing and another implementation of the same port could use a real database. The need for testing should be minimal in this component.
Does Hexagonal Architecture solve all structure needs?
No, there is still a lot more that the team needs to decide on when it comes to coding style and overall structure within these components. Our experience was that this didn't pose a big problem and usually it was just a matter of taking a decision between similar options.
This structure enables us to work in parallel on different components (vertically), e.g. an adapter or a service, for the same feature in an efficient way because they only need a shared contract (port). It even helps us to work in parallel on different parts of the feature (horizontally), e.g. add item or update item in multiple components, at the same time. The merge conflicts are usually pretty small and easy to resolve due to the clear structure.
Closing Remarks
Our experience is that this actually solves a lot of challenging problems at Kognic and creates a great developer environment. Our company has a microservice structure for the code that we produce and applying the concepts previously described is a great fit for our infrastructure. If your company also has a microservice infrastructure, this will most likely be really good steps towards a nice developer experience for you as well.






.png)