Kognic is the leader in autonomy data annotation, providing the most productive annotation platform for sensor-fusion data. We help autonomous vehicle developers integrate scalable, cost-efficient human feedback into their data pipelines—enabling them to train and validate perception systems that are safe, reliable, and aligned with human expectations.
Our Customer Promise: Get the most annotated autonomy data for your budget.
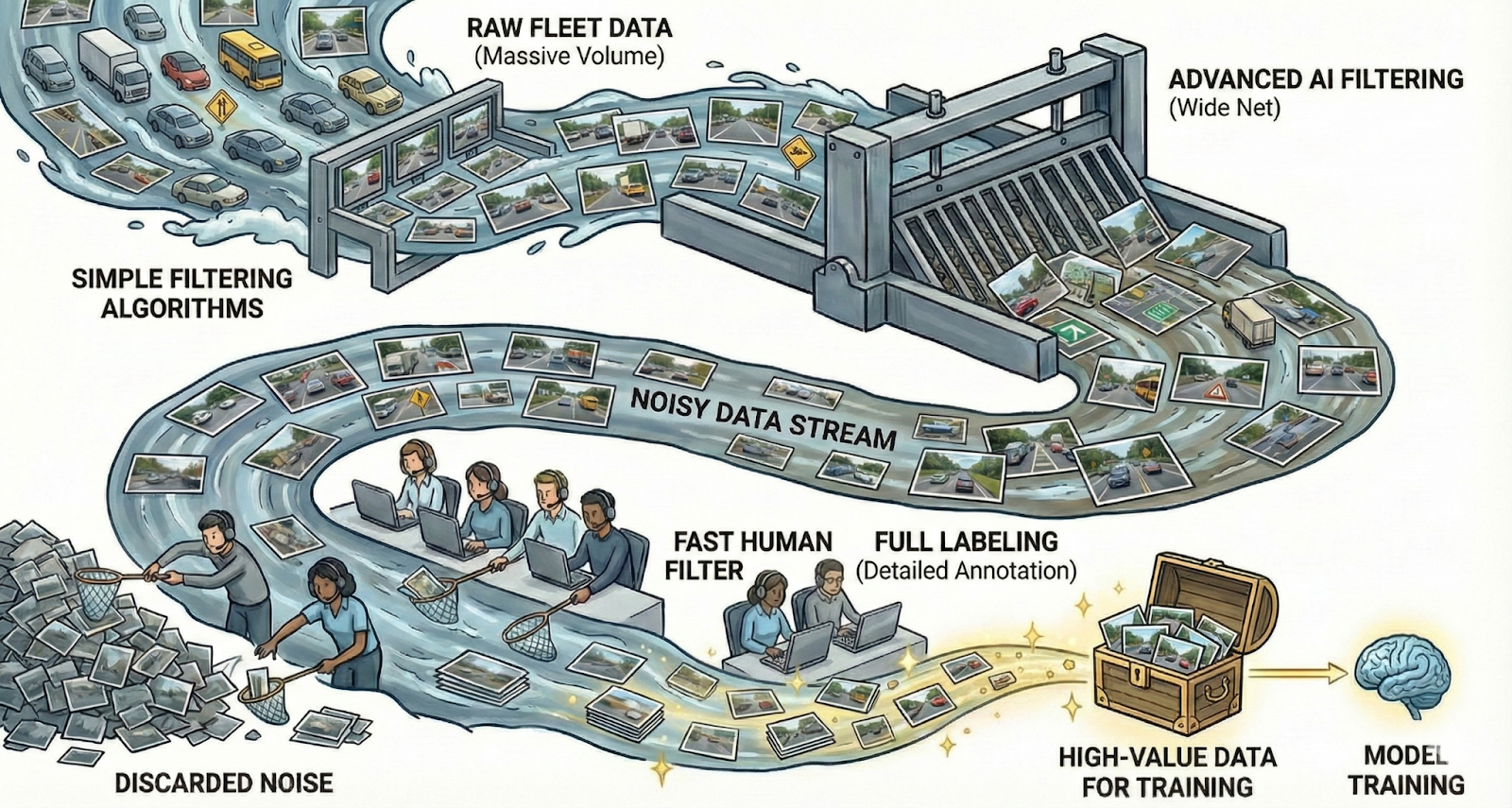
As autonomous systems become more sophisticated, the bottleneck isn't just collecting data—it's transforming raw sensor data into high-quality training signals that accelerate model development. Kognic solves this critical challenge by combining intelligent automation with expert human judgment, helping you maximize the value of every annotation dollar.
The Long Tail Challenge: Why Human Feedback Matters
The real world presents uneven data distribution challenges for autonomous systems. While common scenarios like urban driving provide abundant examples of vehicles and pedestrians, safety-critical edge cases—crossing animals, children on bicycles, unexpected obstacles—remain rare but potentially life-threatening.
Machine learning models require balanced datasets where rare-but-important scenarios are intentionally over-represented. Neural networks need multiple exposures to these critical events to properly encode them; otherwise, they're forgotten when optimizing for common cases. This is where human feedback becomes essential—identifying, curating, and annotating the scenarios that matter most for safety.

This visualization from the NuScenes dataset illustrates the data imbalance challenge—common objects receive substantially more sensor attention than rare but safety-critical classes.
Efficient Scenario Discovery: Finding What Matters
Autonomous vehicles must demonstrate reliable performance throughout their entire Operational Design Domain (ODD). Meeting regulatory standards requires comprehensive testing coverage across all behavioral competencies and scenarios.
Traditional approaches involve teams manually reviewing countless hours of fleet recordings or conducting expensive "labeling safaris." Kognic transforms this process by enabling development teams to efficiently search previously collected fleet data, making traditional manual discovery methods obsolete.
Our platform accelerates scenario discovery while helping you organize findings into purpose-built datasets for targeted training or evaluation. One-click annotation requests streamline the workflow, and our intuitive interface lets developers instantly flag interesting scenarios for future model refinement or benchmarking.
Model-Guided Active Learning: Annotate What Matters Most
Understanding where your perception models struggle is critical for efficient development. Kognic enables you to upload model predictions and uncertainty metrics for each frame and object, letting you filter unannotated data based on model performance.
This creates a powerful feedback loop—continuously identifying where your model makes mistakes and prioritizing those areas for annotation. By focusing on objects near decision boundaries through uncertainty metrics, you strategically allocate annotation resources to deliver the greatest performance improvements per dollar spent.
Advanced Discovery Through Visual Similarity and Natural Language
When engineering teams identify problematic scenarios, finding similar situations typically requires extensive manual review. Kognic's platform addresses this with two powerful capabilities:
- Visual similarity search across your entire dataset
- Natural language query for intuitive data exploration
Our experience shows that combining these approaches yields the best results—using natural language to identify initial scenarios, then refining through visual similarity to build comprehensive training sets.
The Most Productive Platform for Autonomy Data
Kognic's platform powers an iterative development cycle: identify model weaknesses, strategically annotate relevant data, and continuously evaluate performance improvements. This approach dramatically accelerates perception development while optimizing your annotation budget.
Why customers choose Kognic:
- Price leadership: No one delivers more annotated autonomy data per dollar
- Productivity gains: Purpose-built tools for sensor-fusion annotation deliver up to 68% efficiency improvements
- Smart automation: Intelligent co-pilots and auto-label integration reduce manual effort
- Expert workforce: Domain expertise focused on safety-critical autonomy data
We combine People, Platform, and Process to ensure you get maximum value from your annotation budget—helping you achieve exceptional perception performance and comprehensive validation coverage that satisfies the most demanding regulatory requirements.
Ready to experience how Kognic can accelerate your autonomy development? Contact us to discuss your specific challenges or arrange a platform demonstration with your data.