At Kognic, we believe that machines learn faster with human feedback. Our participation in the Edge AnnotationZ challenge demonstrated how our approach to automatic annotation reflects this core principle—combining the power of machine learning with insights from human annotation workflows to deliver the most productive solution for sensor-fusion data.
Why We Participated: Leading the Frontier of Autonomy Annotation
As the leader in autonomy data annotation, Kognic is committed to pushing the frontier forward. The Edge AnnotationZ challenge offered an opportunity to demonstrate how our deep expertise in human annotation workflows translates into more effective automation strategies. Our goal wasn't just to win—it was to prove that understanding how humans annotate complex sensor-fusion data is the key to building better auto-labeling systems.
Human-Inspired Machine Learning: The Kognic Advantage
Our winning approach was built on a simple but powerful insight: the most productive annotation platform learns from how expert humans work. At Kognic, we've spent years optimizing workflows for annotators working with LiDAR, camera, and radar data. This deep understanding of the human annotation process gave us a unique advantage in designing automatic solutions.
The four observations we applied in the challenge came directly from our experience operating the most productive annotation platform for sensor-fusion data:
- Leveraging model strengths where humans are fastest: Objects close to the vehicle with dense point clouds are easy for both humans and models to identify. By running PointPillars across an enlarged area, we maximized automation where it works best—keeping costs down and productivity high.
- Guiding detection with multi-modal context: Just as our annotators use camera images to identify distant objects with sparse LiDAR returns, we painted 2D predictions onto 3D point clouds. This sensor-fusion approach—core to Kognic's platform—dramatically improved detection of vulnerable road users.
- Optimizing perception through test-time augmentation: Our annotators zoom and adjust brightness to find all objects. We replicated this by feeding images through our networks multiple times with different augmentations, improving robustness without sacrificing speed.
- Using temporal context for better predictions: Annotators naturally use sequence data to distinguish moving objects from static ones. By tracking objects across frames and using temporal consistency, we filled gaps and improved accuracy in our key frames.
Observation 1: objects close to us are easily visible in LiDAR data
In the competition, Zenseact provided us with a so-called PointPillars model which could detect objects in point clouds. When we evaluated this model we found that objects with many detected points were easily detected. In practice, this meant that the model worked well for objects close to us. However, we discovered that Zenseact only ran this model in a small area. We thus ran their model on an enlarged area, and used these detections in our pipeline for our non-key frames.
The fact that the model worked best for objects with many points corresponds to our observation that humans have an easy time with objects close to us. They generally don’t spend much time on such objects, and agree with each other where objects are and what their shape is.
Observation 2: for objects far away, annotators guide themselves through the lidar view using the available images
Although our predictions for vehicles close to us were correct (see observation 1), the PointPillars model supplied by Zenseact was not working well on pedestrians and bikes. The reason why is that these objects only have a few ‘lidar-returns’ on them and thus, they are hard to find for the model.
Luckily, we discovered that these objects were well-detected in our predicted 2D bounding boxes. The annotators will usually follow a pattern to annotate 3D objects with few lidar points: they can highlight a portion of the camera image containing an object of interest. This region is then projected to the 3D world using the knowledge of camera and lidar parameters and will form a pyramid-shaped (frustum) region in the point cloud, which ultimately will help to identify and annotate objects in 3D. We tried to replicate this by painting the classes of the predicted 2D bounding boxes on top of the LiDAR points.


As it can be observed in the first image, the bounding boxes are not a tight-fit around that specific object. And because of that, there is still a lot of ‘bleeding’ of the classes to other points. In this respect, we believe the approach of Horizon Robotics in the Waymo challenge could have helped us here. In their approach, not only 2D bounding boxes are drawn on top of the point cloud, but also semantic segmentation information. Nevertheless, we did not have access to per-pixel semantic information due to the restricted allowed external information we could use during the challenge.
However, and despite the lack of semantic segmentation information, our approach based on using image information in the point cloud worked! So we were able to significantly improve our detection score for vulnerable road users in the frames for which we had image data available.
Observation 3: Annotators change their view on the image by zooming and changing the intensity
The images in the dataset were all very large. This led to our annotators zooming into the image to find all of the objects. In this sense, and to give some background information, not only does the large size of an image make it difficult to find all objects: the differences in brightness can also be confusing for us humans. Fortunately, the Kognic annotation tool allows annotators to zoom in and out, as well as to change the brightness of an image.
Thanks to our experience we know that neural networks function better if we do the same. In other words, instead of feeding your input image once through your network you can feed it multiple times with small changes and aggregate the different predictions. This is called “test time augmentation”, and it consists of feeding the same input in multiple ways to a neural network and averaging the results. During training, the same augmentation methods can be used as a regularization method. As a result, you prevent the overfitting of the network on the training set, and thus improve your performance at inference time.
In the course of the competition we also tried to use ensemble learning to try to account for weakness in individual models. We were hoping that if we trained multiple model architectures we could obtain models which were good at different things. For example, some neural networks are better at detecting large objects (such as cars), while others are better at detecting small objects (such as bikes and pedestrians). We fed the same image to all these different models and hoped that the final result would be better than the one that the individual models could be trained for.
Still, our approach didn’t show a lot of improvements in detection accuracy for our final predictions. Even though the results were promising during the training phase, we believe that the final neural network we trained was performing so well on our test data that there was little improvement by changing the input to the network. In addition, we saw that our best performing 2D model was so much better than the other models in our model ensemble that we decided to only use the output of the best model directly.
Observation 4: It’s easier to identify objects in our keyframe if we see the sequence before the keyframe
The final observation we had when looking at LiDAR data is that it’s easier to distinguish between static and dynamic objects when you look at a sequence of data rather than a single frame. By playing the lidar as a video you can see moving objects go through a scene, even if they only have a few lidar hits on them. At the same time, this makes it easier to place objects correctly, even if they are further away from the ego vehicle or blocked by another object in the key frame that needs to be predicted.
How did we put this into practice? We tried to incorporate this observation into our prediction model by tracking objects in the lidar data in the frames preceding our key frame. Visually, it can be guessed quite easily which objects are probably real and which ones are likely fake if you plot them in an image. In this sense, objects which consistently appear with a consistent orientation are more likely to exist than objects which only exist for a few frames, or change their orientation all the time.
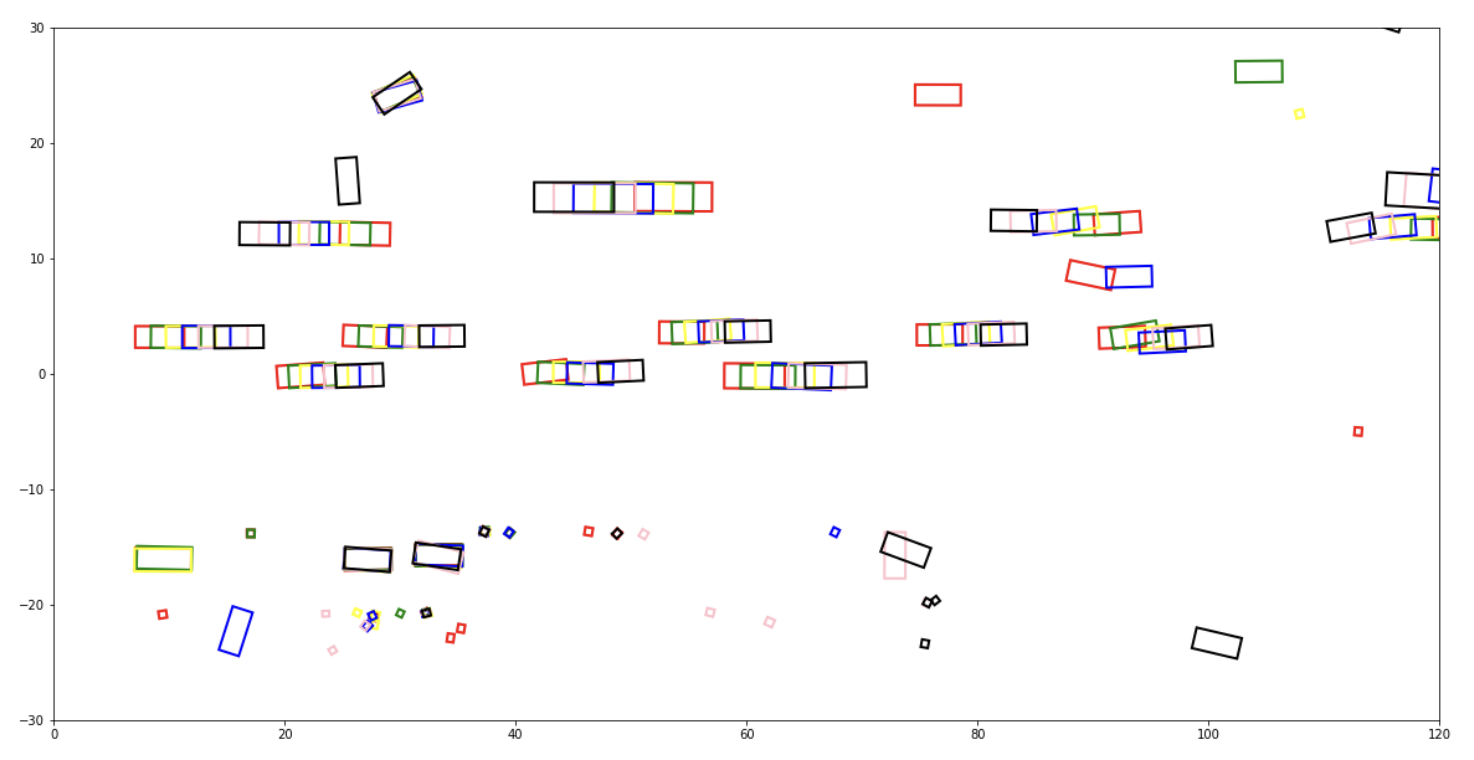
In order to do this, we transformed every detection to the same coordinate system using the odometry data. After that, we used intersection over union for object assignment and a kalman filter to track objects. And then, we used detections in the preceding frames to fill in any missed detection in our key frame.
As a last step we had to connect 2D predictions and 3D predictions. For this purpose, we projected the 3D bounding boxes into the 2D image and used the intersection over union between the predicted 2D boxes and projected 3D bounding boxes to assign them.
Some ideas we tried which didn't work
As the duration of the competition was only two weeks, we were pragmatic and quickly evaluated how well our solutions worked. We would log each experiment together with whether our score improved or not, and whether we leaked any training data in the process (for example, by drawing the ground truth of the 2D bounding boxes on top of the 3D points). Thanks to this approach we rapidly eliminated solutions which sounded nice on paper, but didn’t help us improve on the actual score.
Some examples of such ideas were:
- Augmenting the pointcloud. OpenPCDet has some operations to augment the points based on the bounding boxes. Unfortunately, we saw that the longer we trained, the lower our score became. Although this method should work in theory, in practice we had to drop it quickly.
- Different 3D object detectors. One look at the current top-performing 3D object detectors is enough to realize that there are better methods available than PointNet. Nevertheless, we could not replicate these results on our data. We don’t know what caused this, so we quickly decided to pursue other methods.
- Densifying the point cloud. Instead of only feeding one point cloud frame, we wanted to accumulate several lidar frames simultaneously. Although this dense representation looked good on paper, training was too slow to give us a result during the timespan of the competition.
An inspiring (and victorious) experience
To conclude, we must say that we really enjoyed participating in this challenge. The people we worked with and competed against were both nice and inspiring. And on top of that, we built an algorithm which managed to correctly annotate a large amount of objects. For us at Kognic it is good news that machine learning algorithms can annotate a large amount of objects automatically. This gives our annotators more time to focus on the difficult cases in which current machine learning techniques are underperforming.
The final goal of Zenseact’s challenge was automatically annotating all data with high quality, but we saw in the competition that this is not yet something which can be built in just two weeks. So an interesting next challenge could be whether the algorithm can also reliably indicate which annotations are of high quality and which ones are not. This would enable the algorithm trained on this data to only learn from non-contested areas in the automatically generated training data.
Last but not least, we are glad that our human-inspired method yielded such good results! Not just for the win itself, but because they demonstrate that the lessons learned at Kognic on how humans produce high quality training data can transfer nicely to how machines can produce high quality training data.
Why This Matters for Your Autonomy Program
The lessons from the Edge AnnotationZ challenge have direct implications for anyone building autonomous systems:
- Human expertise accelerates automation: The best auto-labeling systems are built by teams who deeply understand how humans annotate complex data. This is why Kognic's vertically integrated approach—combining platform, process, and people—delivers superior results.
- Sensor-fusion requires specialized tooling: Real-world autonomy data is multi-modal and sequential. Generic annotation platforms can't match the productivity of tools purpose-built for LiDAR, camera, and radar fusion.
- Cost-efficiency comes from smart human-in-the-loop: The future isn't full automation—it's knowing exactly when to use machines and when to leverage human judgment. This is where Kognic's platform excels.
Partner with the Leader in Autonomy Annotation
The Edge AnnotationZ challenge validated what our customers already know: Kognic delivers the most annotated autonomy data per dollar. Our human-inspired approach to automation, combined with our deep expertise in sensor-fusion workflows, makes us the price leader in autonomy data annotation.
Whether you're scaling up data collection for autonomous vehicles, training models for robotics, or validating safety-critical systems, Kognic helps you integrate cost-efficient, reliable human feedback into your data pipeline. Because at the end of the day, machines learn faster with human feedback—and nobody does human feedback for autonomy data better than Kognic.
Ready to accelerate your annotation workflows? Explore how Kognic’s platform combines AI assistance, 3D capabilities, and quality controls. Learn more about the Kognic platform →