In today's rapidly evolving automotive landscape, the race toward autonomy has shifted from "if" to "how fast." With Waymo now averaging 250,000 paid robotaxi rides weekly and BYD shipping its "God's Eye" L2+ ADAS as standard across 21 models, the autonomous revolution is not just coming—it's here.
But there's a critical challenge at the heart of this transformation: how do you consistently onboard thousands of annotators to deliver the high-quality data that safe autonomous systems demand?
The Autonomy Data Explosion
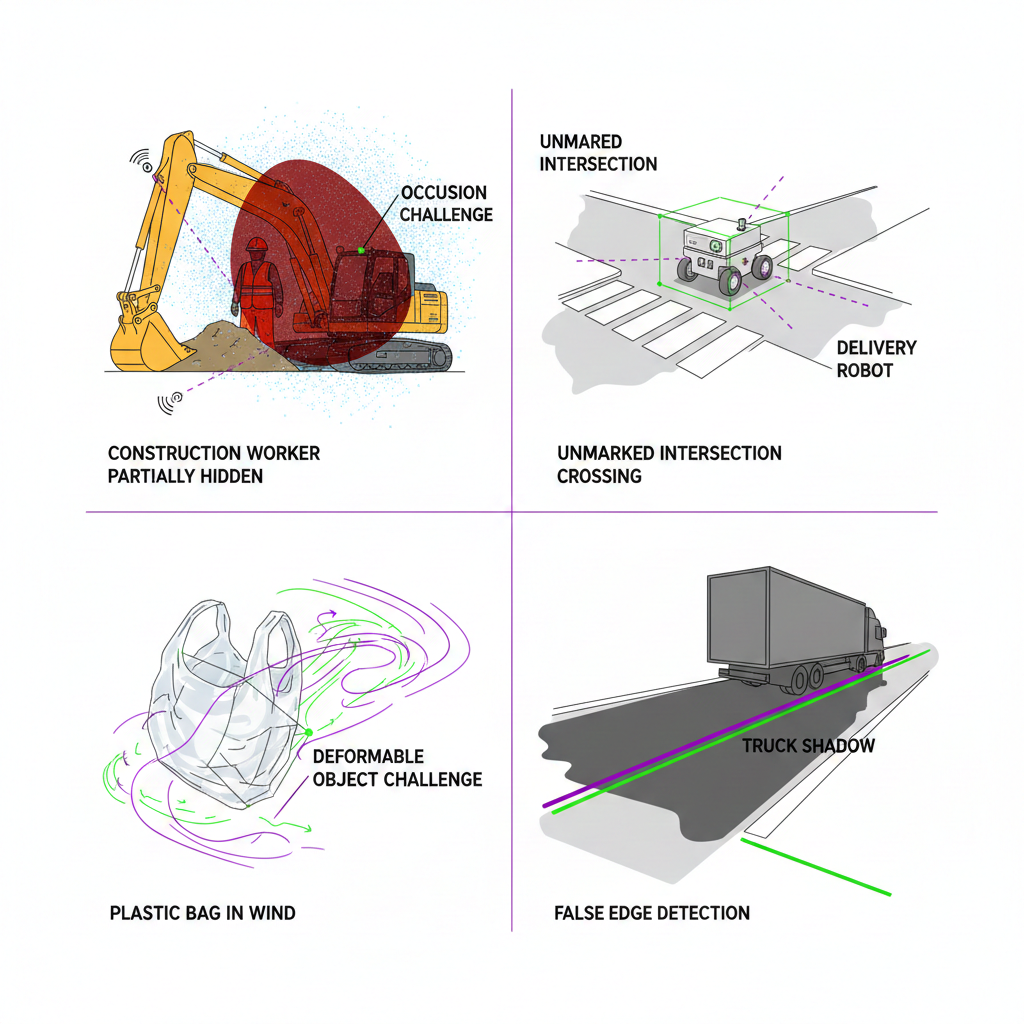
By 2030, more than 70 million vehicles annually will feature L2 or higher autonomous capabilities. Each of these vehicles can generate up to 4TB of raw sensor data daily—creating a tidal wave of information that must be accurately annotated to train reliable AI systems.
This isn't just about volume. As regulatory frameworks like UNECE WP.29, ISO 26262, and the EU AI Act evolve, the demand for human-verified, traceable ground-truth data is becoming non-negotiable. The stakes couldn't be higher: inconsistent annotations create real safety risks for autonomous systems navigating our roads.
Raw

The Kognic Difference: Quality at Scale
At Kognic, we've built the world's most productive annotation platform for autonomy data, specifically designed to tackle these challenges head-on. Our Kognic Annotator Academy doesn't just process annotations—it creates a systematic approach to building annotation teams that deliver consistent, high-quality results across millions of data points.
What sets our approach apart is the seamless integration of People, Platform, and Processes:
- People: Domain experts and a globally scaled workforce operating under strict ethical standards
- Platform: Purpose-built to minimize human effort while maximizing annotation quality and productivity
- Processes: Battle-tested workflows that ensure consistency and predictability at scale
This powerful combination has enabled us to deliver over 100 million annotations across seven years of operations, with deployments spanning the U.S., Europe, China, and Japan.
Driving Real Business Value
For automotive leaders navigating the autonomy transformation, our approach delivers concrete business advantages:
- Cost efficiency: No one delivers more annotated autonomy data per dollar, helping teams maximize their annotation budget
- Faster time-to-market: Our streamlined processes reduce iteration cycles, accelerating development timelines
- Regulatory readiness: Human-verified annotations provide the audit trail and traceability that regulators increasingly demand
- Quality assurance: Consistent annotations mean safer, more reliable autonomous systems
As the autonomous vehicle landscape continues to evolve, one thing remains constant: the need for trustworthy, high-quality data to power safe, reliable AI systems. By bringing together the right people, platform, and processes, Kognic ensures that your autonomy programs have the solid data foundation they need to succeed.
The future of transportation is autonomous—and at Kognic, we're making sure it's built on a foundation of quality.