Machines Learn Faster with Human Feedback: Data exploration
Autonomous systems require more than just data—they need precise, validated human judgment to learn safely and reliably.
Machine learning for autonomy is fundamentally about aligning models with human expectations. With autonomous systems, the annotated training data—not just the program code—instructs machines how to behave safely in the real world. Much like complex software is best developed iteratively, the same principle applies to training data. The traditional waterfall approach has proven inadequate for machine learning in safety-critical applications. Modern machine learning relies on iteration at multiple levels:
- Collect data iteratively. With strict performance requirements, it's impossible to know upfront how much data is needed. You must learn what's sufficient as you progress.
- Define annotation requirements iteratively. Annotation instructions cannot be fully specified at the project's start. New edge cases emerge, and the relationship between training data characteristics and model performance isn't always predictable. Start with informed assumptions, test, and refine.
- Improve annotation quality iteratively. Mistakes are inevitable, and catching every error through multiple reviews is neither feasible nor cost-effective. By improving annotation quality in parallel with model development, you can identify and fix the most critical issues efficiently.
Introducing Data Exploration
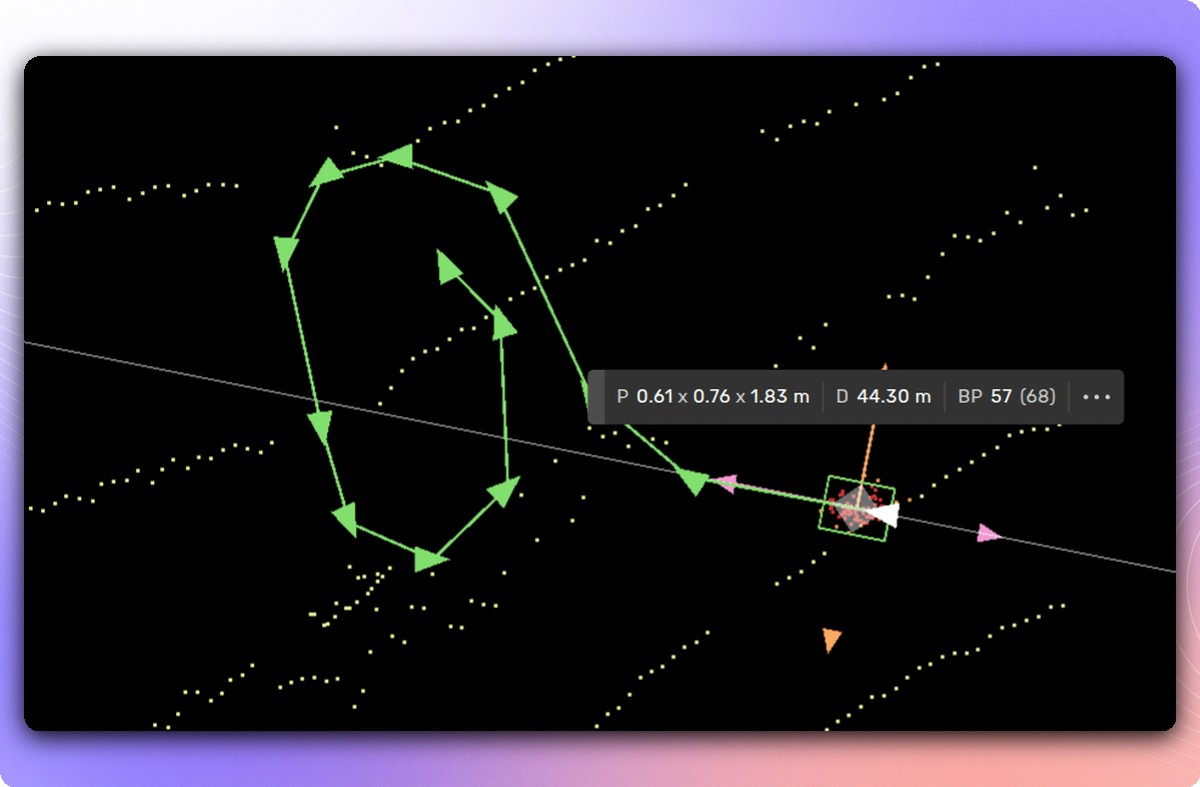
To support this iterative approach, we're introducing Data Exploration—a powerful new capability within our platform that accelerates your feedback loop. Exploration enables teams to compare annotations against predictions and efficiently browse results, helping you quickly identify where human judgment matters most. With advanced sorting, filtering, and search capabilities, you can pinpoint the exact data points that will have maximum impact on model performance.
Comparing annotations to predictions is straightforward in concept but invaluable in practice. With high-quality annotations and a well-trained model, you'd expect close alignment. However, hunting down discrepancies proves doubly valuable: sometimes it reveals annotation errors that need correction; other times, it exposes areas where the model itself needs improvement.
Beyond the convenience of accessing millions of comparisons with rich visualizations and powerful filtering—all through your browser—Explore integrates seamlessly into the Kognic platform's review workflow. When your team spots something that needs closer inspection, annotations can be sent back for manual review and correction. By using Explore to target only the data that requires refinement, quality assurance becomes dramatically more streamlined and cost-efficient. No more blind double-checking of entire datasets. Updated annotations flow back through the same delivery pipeline as all other annotations.
At Kognic, we believe that machines learn faster with human feedback—and that feedback must be integrated iteratively to succeed. Explore makes this real, helping autonomy teams deliver the most annotated data for their budget while maintaining the quality and alignment that safety-critical systems demand.
Share this
Written by