Since joining the ADAS/AD space in 2019, I've seen countless presentations about "data lakes" and "scenario libraries" from companies sitting on petabytes of data. But is this data the treasure trove it's made out to be? As an AI expert once told me: "Everyone likes to talk about how valuable their data lake is - but I have yet to see a single company list it as an asset on their balance sheet."

ML Shangri-La or cost sink? The value of data lakes heavily depends on their utilization.
For ML-based product development, proprietary data is absolutely a huge asset. But as Andrew Ng says when he talks about data-centric AI, in a market where everyone has access to the same algorithms, product success depends on the effectiveness of your data effort. However, just as with code, a lot of data doesn't equal a lot of progress.
Data is an asset with a short half-life. Your camera supplier discontinues models. LiDAR resolution becomes outdated. New automation processes require better sensors. Your scope extends to objects previously considered irrelevant—and entirely new objects emerge: people in masks during Covid, e-scooters, delivery bots, robotaxis. All datasets inevitably suffer from data drift as the world keeps changing.

The value of static datasets inevitably suffer from data drift and knowledge drift.
There's another problem: alignment—ensuring machines behave the way humans intend. You can't know which data types improve model performance until you start training, and what moves the needle changes over time. At first, you can improve perception by adding more labeled examples. Eventually, you hit diminishing returns: 500k more labeled cars won't improve your recall for lost cargo. You can't map your long tail until you're deep into development.
Just as data drift is inevitable, you'll experience "knowledge drift"—initial assumptions about data needs give way to new insights. If you're limited to data recorded before your problem was known, having suitable training data comes down to luck. And luck is a poor substitute for strategy.
The Limitation of Linear Data Pipelines
Legacy automotive companies sometimes counter uncertainty through over-specification: I've seen sourcing RfQs outlining data needs 4 years into the future, detailed over thousands of Excel lines—hundreds of which get dropped days before proposals are due.
Current "data pipeline" efforts in many companies are waterfall models, looking something like this:

Linear data sourcing efforts make it a challenge to flexibly adapt actual ML development progress.
This attempts to build software the way one builds cars—resulting in low budget effectiveness. You'll overspend on data for overestimated needs while suffering coverage gaps for unexpectedly relevant data. Thinking about your data effort as "do once" means setting yourself up for expensive disappointment.
Machines Learn Faster with Human Feedback
So what should companies do with massive data amounts they're already sitting on? While no one can offer a silver bullet to mitigate all data drift challenges, there are ways to increase the usefulness of legacy data without starting from scratch every time.
Rather than estimating needs upfront, we believe in accurately quantifying them along the way—enabling smaller, more budget-effective decisions based on quantification. This is achieved by integrating your data effort with ongoing ML model development. The overall process we propose for supervised learning is outlined in this article.

Using model predictions to analyze training datasets and vice versa: Integration of data/development efforts allows for faster iteration
Treat your dataset as an asset that's "under development" just as much as your algorithms—requiring adequate developer tools, just as working with code does. Use your model-under-development to surface maintenance-relevant portions in your datasets, so they can be updated (not re-annotated from scratch) and made available in the configuration you need for current training efforts.
The Case for Integrating Data and Model Development
If you want to keep ROI for your data lake at an acceptable level, you need to invest in maintenance. Just as any codebase will degrade and drown you in technical debt if not kept up-to-date, the same happens to data.
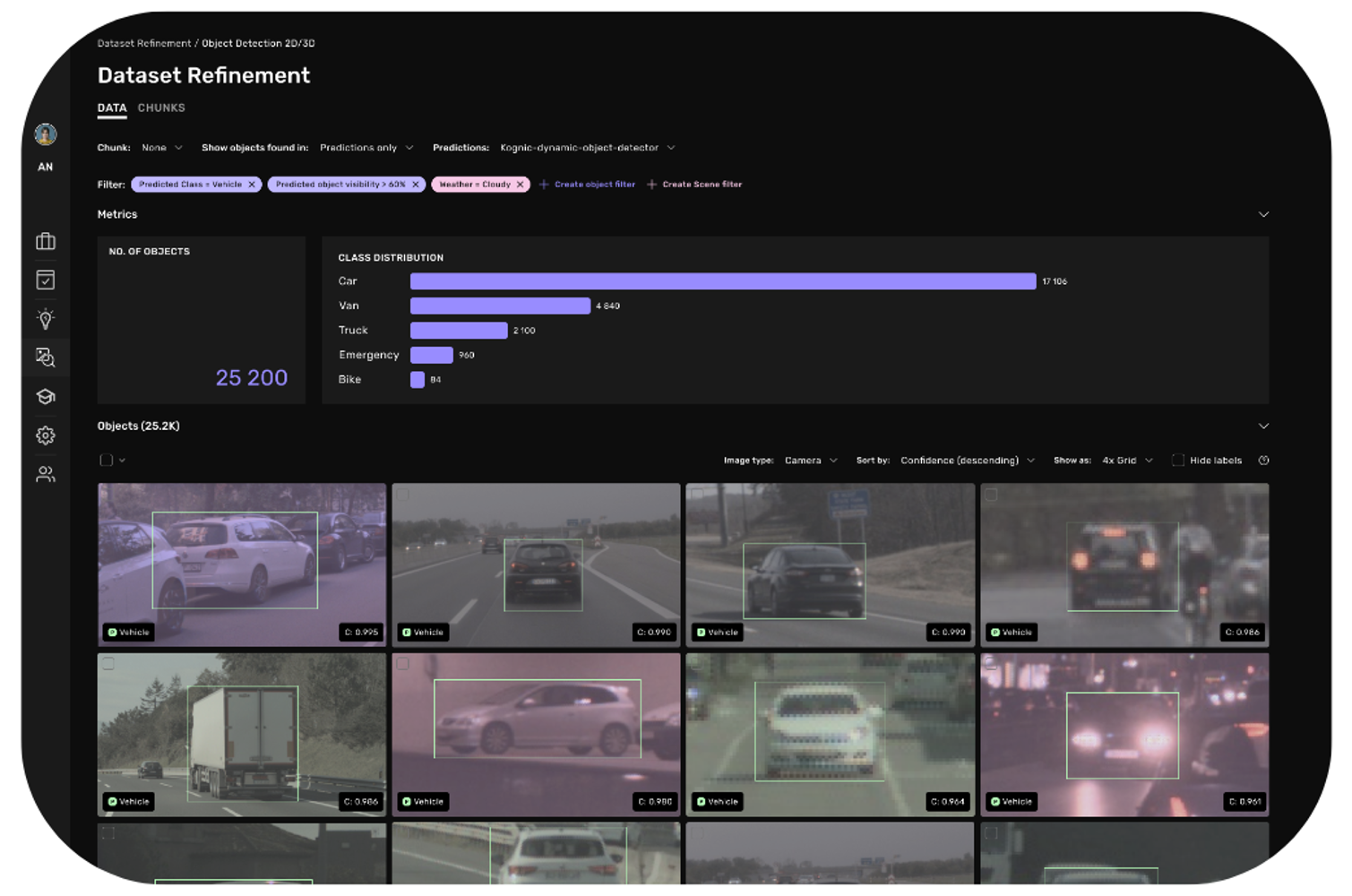
Regularly maintaining your data lake makes sense—lest you end up with a swamp. The results speak for themselves: The first customer to try Kognic's exploration tools found it to be the initiative with the single-biggest impact on their ADAS perception development during the whole year.
We want to build more proof—and that's where you come in. Kognic is looking for additional customers to test drive our tools in a limited-time pilot engagement—either using existing ground truth data or in an entirely new effort with unclear data needs.
If you believe in iterative software development and agree that iterative thinking must extend to the data effort, we want to talk to you. Kognic helps you integrate cost-efficient, scalable human feedback into your data pipelines—enabling you to get the most annotated autonomy data for your budget. Hit the "Book a Demo" button in the top right, or reach out via my email below. We look forward to exchanging thoughts!