
In this blog post, we talk about...
- why the quality of annotated data is important, and some ways to quantify it
- why it is expensive to measure the annotation quality of a dataset
- how we use statistics at Kognic to cost-efficiently infer the annotation quality of a dataset
Data is the single most important component in modern machine learning applications, including perception systems in autonomous vehicles. Much like the eyes and ears of a human, the cars of today and tomorrow are equipped with a multitude of sensors that collect information that is fed into a computer in the car. This information has to be processed and interpreted in real-time so that the car understands what lies ahead on the road while it is driving. However, the algorithms on the computer onboard the car need training on how to do that interpretation. This is where we enter the game, since Kognic can provide annotated data which is needed when doing such training.
2D Bounding Box

3D Cuboid
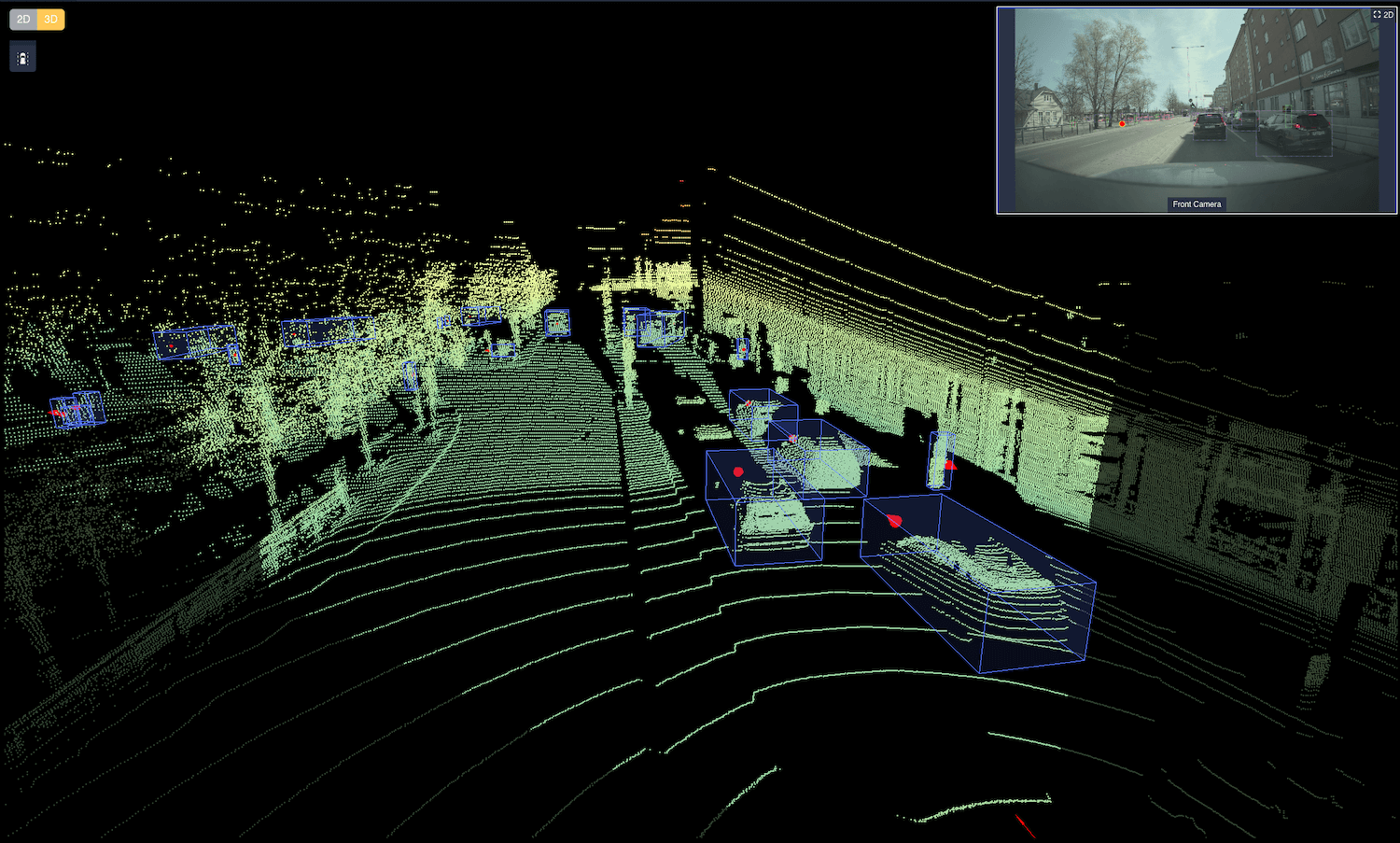
Annotated data is paramount when preparing the perception system of a car with some level of autonomy for the streets. It serves two purposes; training the algorithms on the computer onboard the car to interpret the collected information, as well as validating that the computer indeed has learned to correctly interpret collected information. Since annotated data is used for both these critical purposes, the quality of the annotations are of utmost importance. Low quality annotations might, in the end, cause a car to misinterpret what is happening on the road.
The process of annotating data always includes some human decisions. The first challenge is actually to have humans agree on what is a correct annotation of the recorded data, and creating such annotation guidelines is sometimes not as easy as one might think. We are experienced in how to efficiently design annotation guidelines that enhance the quality, and we will share some of our insights in a later blog post.
The second challenge is to perform the annotations at scale, guided by the guidelines. At Kognic we have human annotators working in a carefully designed environment assisted by machine learning algorithms to annotate large amounts of data as efficiently as possible. We will share more about our experience also on these topics in later blog posts.
We understand that the annotations are safety-critical, but also that they have to be acquired cost-efficiently for our customers. Our top priority is therefore to continuously develop and optimize our annotation tools and processes. To guide this development we need tools for measuring annotation quality, so that we can ensure we always reach the required quality while also increasing annotation efficiency. This is much of an ongoing process, as there are many different aspects of data quality and it is not yet fully known what impact the different aspects have to modern machine learning methods. Kognic is of course taking an active part in advancing the knowledge.
One way to quantify annotation quality is the precision and recall of an annotated dataset. Let us explain what it means: consider the type of annotations where an object (like an approaching vehicle) in a camera image is annotated by a bounding box. When reasoning about the quality of such a dataset, two important questions are (i) whether an object of interest has been correctly annotated by a bounding box, and (ii) whether a bounding box actually contains an object of interest.





In a perfectly annotated dataset, neither of the above mistakes are present. One way to define quality is therefore to compute to which extent these mistakes are present in an annotated dataset. We could for instance compute
- The ratio of bounding boxes that actually denotes an object. This is known as the precision. Ideally the precision is 1.
- The ratio of objects that are correctly annotated with a bounding box. This is known as the recall. Ideally the recall is 1.
But computing the precision and recall for a dataset would also require a manual critical review of each frame in the entire dataset, which could be as expensive as the annotation process itself! To gain efficiency when we compute precision and recall, we therefore rely on statistics to infer the precision and recall. We therefore do a manual critical review only for a statistically well chosen subset of all annotations, and use probability theory for drawing conclusions about the entire dataset.
In more detail we use a Bayesian approach to compute the posterior distribution for the precision and recall for the entire dataset, conditional on the subsample of critically reviewed annotations that we have made. It does not only give us an estimate of the precision and recall, but also quantifies the uncertainty in these estimates. We can for example compute the so-called lower 95% credibility bound, meaning a threshold that we are 95% sure that the precision or recall does not fall below. You can explore how it works in the animation below. The more manual reviews that we make the less uncertainty is left in our estimate of the precision and recall, and we can explicitly decide on the trade-off between the cost of manual critical reviews and the acceptable level of uncertainty in our quality measures.
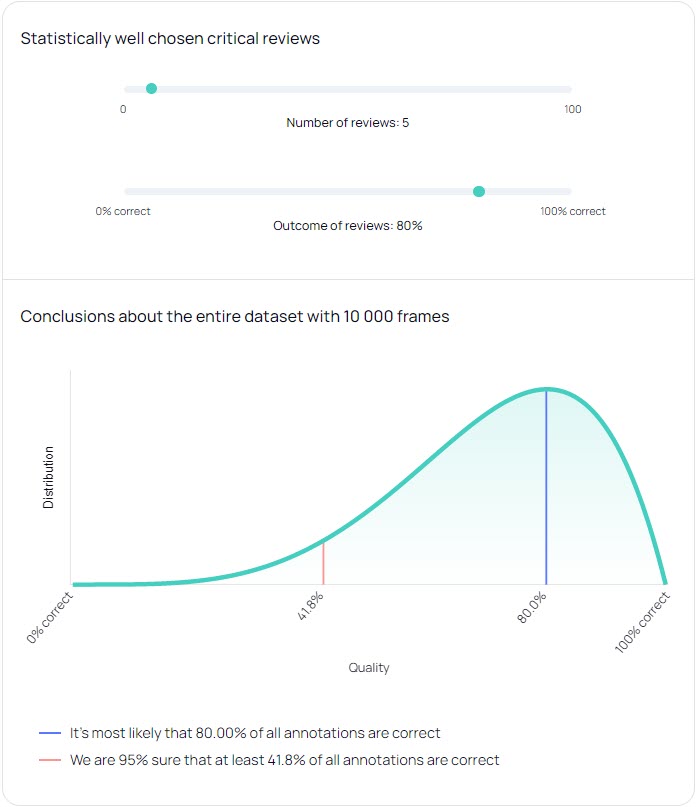
All in all, this gives us a cost-efficient tool for measuring the quality of our annotations in terms of precision and recall levels, and how certain we are about the levels. It has become an integral part of our product today that we use routinely. We also compute similar quality measures also for other aspects of our annotations, such as overlap ratios of bounding boxes in 2D and 3D, etc. Measuring the quality of our annotations is very helpful when optimizing our processes, and we believe this is a necessary step on the road to ensure the performance of perception systems in autonomous vehicles.
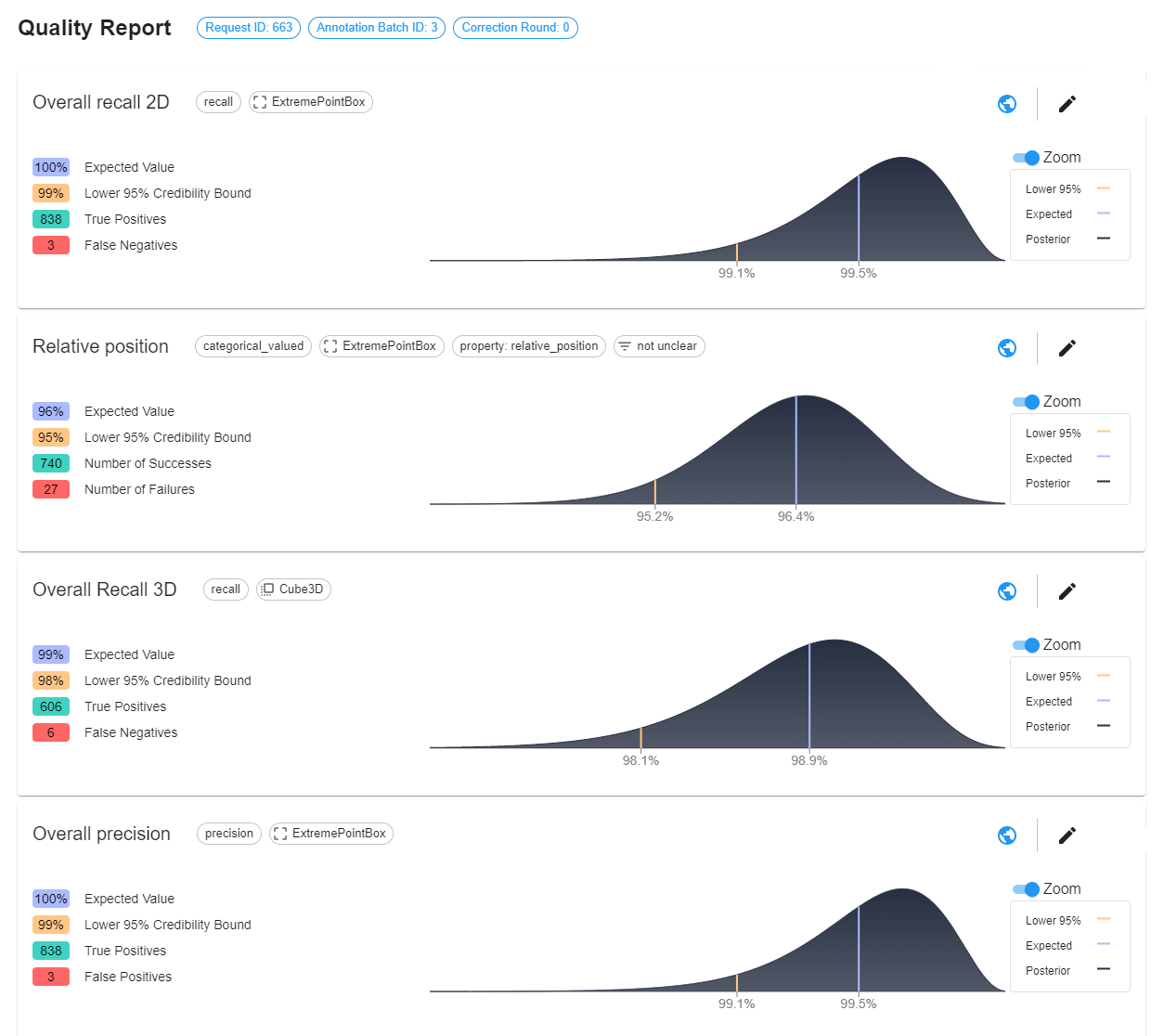
The above image shows a screenshot from our platform, where this idea is implemented and used as an integral part of our continuous quality assessment of our annotations.

